What is LitServe?
您是否身為一位 AI 開發者或工程師,卻花費過多時間與基礎設施搏鬥,而非專注於模型創新?LitServe 是一款彈性且易於使用的伺服引擎,旨在簡化任何 AI 模型的部署,無論模型大小或框架為何。LitServe 建構於廣受歡迎的 FastAPI 框架之上,消除了擴展、批次處理和 GPU 管理的複雜性,讓您專注於真正重要的事情:AI 的效能。
主要特色:
⚡️ 加速伺服效能: 相較於標準的 FastAPI 實作,體驗至少兩倍的速度提升,這歸功於 LitServe 針對 AI 工作負載而設計的優化多工處理能力。
⚙️ 透過 LitAPI 和 LitServer 簡化部署: 輕鬆組織您的程式碼。LitAPI 定義您的模型如何處理請求,而 LitServer 則管理擴展、批次處理和串流的複雜性,所有這些都不需要深厚的基礎設施專業知識。
🤖 部署任何模型、任何框架: 帶上您自己的模型!LitServe 支援各種框架,包括 PyTorch、JAX、TensorFlow 等。它專為多功能性而設計,可以處理從 LLM 到傳統機器學習模型的所有內容。
🚀 透過自動 GPU 管理輕鬆擴展: LitServe 會自動在可用的 GPU 上擴展您的模型,從而最大程度地利用資源。它還支援批次處理和串流,進一步增強生成式 AI 應用程式的效能。
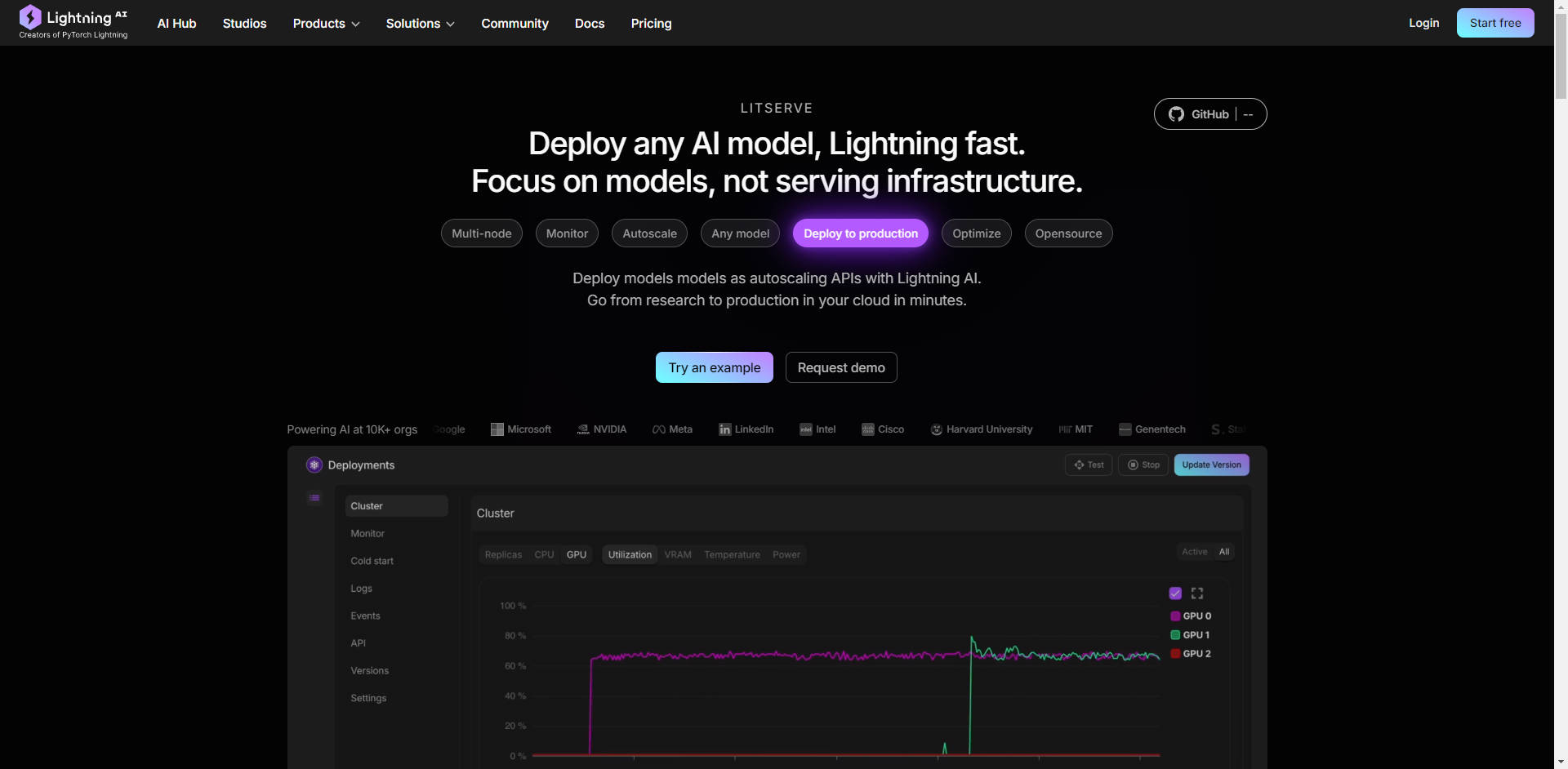
☁️ 隨處部署,完全掌控: 選擇您的部署環境。在您自己的基礎設施上運行 LitServe 以實現完全控制,或利用 Lightning AI 的託管平台進行自動監控、自動擴展和容錯。
使用案例:
高吞吐量文字生成: 假設您開發了一個用於生成行銷文案的客製化大型語言模型 (LLM)。透過 LitServe,您可以部署此模型來處理數千個並發請求,確保您的整個行銷團隊都能快速生成內容,而無需擔心伺服器瓶頸。
即時影像處理: 您建立了一個電腦視覺模型,用於即時分析來自安全攝影機的影像。LitServe 使您能夠在邊緣設備或雲端上部署此模型,同時處理多個視訊串流,並為關鍵事件提供即時警報。這一切都藉由多 GPU 支援和優化的伺服實現。
用於客戶支援的複合 AI 系統: 您需要一個系統,該系統首先轉錄客戶的語音詢問(使用語音轉文字模型),然後分析情緒和意圖(使用 NLP 模型),最後生成個人化的回應(使用 LLM)。LitServe 允許您將這些模型無縫地鏈接在一起,從而創建一個強大而高效的客戶支援解決方案。
結論:
LitServe 使您能夠以空前的速度和效率從模型開發轉向生產部署。其靈活的架構,結合強大的擴展能力和對任何 AI 模型的支援,使其成為開發人員尋求將其 AI 創新推向世界的理想解決方案。停止與基礎設施搏鬥,開始專注於真正重要的事情 – 您的 AI。
常見問題:
LitServe 和 vLLM 之間有什麼區別?
LitServe 的抽象層級比 vLLM 等伺服器更低。您可以將 LitServe 視為一種基礎工具,可讓您建立自己的專用伺服解決方案,例如客製化的 vLLM 伺服器。vLLM 是一種專為 LLM 優化的預構建解決方案,而 LitServe 則為任何類型的 AI 模型提供更廣泛的靈活性。
我可以將 LitServe 與現有的 FastAPI 專案一起使用嗎?
可以,LitServe 建立在 FastAPI 之上,並且設計為易於整合。它透過 AI 特定的功能來增強 FastAPI,從而提高其效能和模型伺服的可擴展性。
使用 LitServe 需要什麼樣的技術專業知識?
LitServe 專為熟悉使用 Python 並對部署機器學習模型有一定的了解的 AI 開發人員和工程師而設計。即使您不是深度學習基礎設施專家,提供的程式碼範例和文件也使您可以輕鬆上手。
使用 LitServe 可以期望節省多少成本? LitServe 具有諸如 scale-to-zero(無伺服器)、可中斷實例、批次處理和串流等功能,可以大幅降低伺服成本。例如,使用 1 美元,Llama 3.1 可獲得 366k 個 tokens,chatGPT 可獲得 25K 個 tokens。此外,該模型在您安全的雲端上運行,具有專用容量。
在 Lightning AI 平台上使用 LitServe 有什麼好處?
在 Lightning AI 上部署可提供額外的好處,包括自動監控、自動擴展(從零到數千個 GPU)、容錯和簡化的管理。它簡化了部署過程並提供企業級功能。
More information on LitServe
Launched
2017-12
Pricing Model
Free
Starting Price
Global Rank
89547
Follow
Month Visit
464.6K
Tech used
Google Tag Manager,Cloudflare CDN,Google Fonts,Gzip,JSON Schema,OpenGraph,Progressive Web App,HSTS
Top 5 Countries
19.19%
8.05%
6.32%
3.97%
3.62%
United States
India
Germany
Vietnam
Kazakhstan
Traffic Sources
2.26%
0.62%
0.09%
7.48%
48.35%
41.21%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 25, 2025)
LitServe was manually vetted by our editorial team and was first featured on 2025-03-10.