
2025年最好的 Hugging Face Agent Leaderboard 替代方案
-

即時的 Klu.ai 資料為此排行榜提供動力,用於評估 LLM 供應商,讓您能夠根據自身需求選擇最佳的 API 和模型。
-
TaskingAI 將 Firebase 的開發簡便性帶入 AI 原生應用程式開發。您的專案可以從選擇一個 LLM 模型開始,打造一個由有狀態 API 支援、反應靈敏的助手,並透過受控記憶體、工具整合以及增強式生成系統,進一步強化其功能。
-

-

利用一套完整的工具,讓您輕鬆探索、測試與整合,簡化並加速 Agent 開發流程。
-

DeepAgent 是一款能整合各系統的 AI 代理,助您無需程式碼即可自動化繁瑣任務,並輕鬆打造專屬應用程式。內建一套完整的 AI 工具。
-
-

-

LLMO Metrics:追蹤並優化您的品牌在 AI 回答中的能見度。確保 ChatGPT、Gemini 及 Copilot 都能推薦您的企業。掌握 AEO。
-

-

別再猜測您的 AI 搜尋排名了。LLMrefs 能追蹤 ChatGPT、Gemini 等平台的關鍵字。取得您的 LLMrefs 分數,並在排名上超越競爭對手!
-

Agent.so: 專為您打造的智慧AI平台,讓您能運用自有資料,輕鬆建立、訓練專屬AI代理,並與其互動對話。透過頂尖AI模型,全面提升您的生產力與業務成長。
-

-

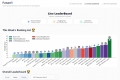
SEAL 排行榜顯示,OpenAI 的 GPT 系列大型語言模型 (LLM) 在用於評估 AI 模型的四個初始領域中的三個領域中排名第一,Anthropic PBC 的熱門 Claude 3 Opus 在第四個類別中奪得第一。Google LLC 的 Gemini 模型也表現出色,在幾個領域中與 GPT 模型並列第一。
-

探索柏克萊函數呼叫排行榜(也稱為柏克萊工具呼叫排行榜),了解大型語言模型 (LLM) 準確呼叫函數(又稱工具)的能力。
-

-

-
-

-
利用 TradingAgents 這款開源多代理人框架,深入探索人工智慧交易領域的研究。模擬企業的分析、辯論,以及風險管理決策。
-

-
-

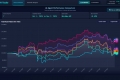
LiveBench 是一個大型語言模型基準測試,每月從不同來源獲得新問題和客觀答案,以進行準確評分。目前包含 6 個類別的 18 個任務,並將陸續增加更多任務。
-

DotAgent 是一個革命性的 AI 平台,搭載 Agent Genome 技術。效能比 GPT-4 強大 8 倍,成本節省高達 95%。非常適合尋求高效 AI 的企業。
-

Abacus.AI 是全球首個端到端的機器學習 (ML) 與大型語言模型 (LLM) 運營平台,在此平台上,由 AI,而非人類,建構應用型 AI 代理程式與系統。
-

-

-

Huggingface 的 Open LLM Leaderboard 目標是促進語言模型評估的開放合作與透明度。
-

WildBench 是一個先進的基準測試工具,用於評估 LLM 在各種真實世界任務中的表現。對於那些希望提升 AI 效能並了解模型在實際情境中的局限性的人來說,它是必不可少的工具。
-

AI 模型決策器簡化了 AI 模型選擇。獲得個人化推薦,節省時間,訪問頂級模型。開發人員、營銷人員和教育工作者的免費工具。提高生產力!
-
Notch: The AI ad generator that turns static assets into high-ROAS animated ads in minutes. Beat creative fatigue & scale your campaigns faster.