
Best LiveBench Alternatives in 2026
-

WildBench is an advanced benchmarking tool that evaluates LLMs on a diverse set of real-world tasks. It's essential for those looking to enhance AI performance and understand model limitations in practical scenarios.
-

BenchLLM: Evaluate LLM responses, build test suites, automate evaluations. Enhance AI-driven systems with comprehensive performance assessments.
-

Launch AI products faster with no-code LLM evaluations. Compare 180+ models, craft prompts, and test confidently.
-

Companies of all sizes use Confident AI justify why their LLM deserves to be in production.
-

xbench: The AI benchmark tracking real-world utility and frontier capabilities. Get accurate, dynamic evaluation of AI agents with our dual-track system.
-

Deepchecks: The end-to-end platform for LLM evaluation. Systematically test, compare, & monitor your AI apps from dev to production. Reduce hallucinations & ship faster.
-

Braintrust: The end-to-end platform to develop, test & monitor reliable AI applications. Get predictable, high-quality LLM results.
-

Explore The Berkeley Function Calling Leaderboard (also called The Berkeley Tool Calling Leaderboard) to see the LLM's ability to call functions (aka tools) accurately.
-

Huggingface’s Open LLM Leaderboard aims to foster open collaboration and transparency in the evaluation of language models.
-

Real-time Klu.ai data powers this leaderboard for evaluating LLM providers, enabling selection of the optimal API and model for your needs.
-

Web Bench is a new, open, and comprehensive benchmark dataset specifically designed to evaluate the performance of AI web browsing agents on complex, real-world tasks across a wide variety of live websites.
-
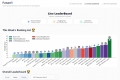
FutureX: Dynamically evaluate LLM agents' real-world predictive power for future events. Get uncontaminated insights into true AI intelligence.
-

BenchX: Benchmark & improve AI agents. Track decisions, logs, & metrics. Integrate into CI/CD. Get actionable insights.
-

ZeroBench: The ultimate benchmark for multimodal models, testing visual reasoning, accuracy, and computational skills with 100 challenging questions and 334 subquestions.
-

Choose the best AI agent for your needs with the Agent Leaderboard—unbiased, real-world performance insights across 14 benchmarks.
-

Evaluate & improve your LLM applications with RagMetrics. Automate testing, measure performance, and optimize RAG systems for reliable results.
-

Stop guessing your AI search rank. LLMrefs tracks keywords in ChatGPT, Gemini & more. Get your LLMrefs Score & outrank competitors!
-

The SEAL Leaderboards show that OpenAI’s GPT family of LLMs ranks first in three of the four initial domains it’s using to rank AI models, with Anthropic PBC’s popular Claude 3 Opus grabbing first place in the fourth category. Google LLC’s Gemini models also did well, ranking joint-first with the GPT models in a couple of the domains.
-

LightEval is a lightweight LLM evaluation suite that Hugging Face has been using internally with the recently released LLM data processing library datatrove and LLM training library nanotron.
-
Evaluate Large Language Models easily with PromptBench. Assess performance, enhance model capabilities, and test robustness against adversarial prompts.
-

Unlock robust, vetted answers with the LLM Council. Our AI system uses multiple LLMs & peer review to synthesize deep, unbiased insights for complex queries.
-

Geekbench AI is a cross-platform AI benchmark that uses real-world machine learning tasks to evaluate AI workload performance.
-
Stax: Confidently ship LLM apps. Evaluate AI models & prompts against your unique criteria for data-driven insights. Build better AI, faster.
-

Instantly compare the outputs of ChatGPT, Claude, and Gemini side by side using a single prompt. Perfect for researchers, content creators, and AI enthusiasts, our platform helps you choose the best language model for your needs, ensuring optimal results and efficiency.
-
Evaligo: Your all-in-one AI dev platform. Build, test & monitor production prompts to ship reliable AI features at scale. Prevent costly regressions.
-

Struggling to ship reliable LLM apps? Parea AI helps AI teams evaluate, debug, & monitor your AI systems from dev to production. Ship with confidence.
-
Weights & Biases: The unified AI developer platform to build, evaluate, & manage ML, LLMs, & agents faster.
-

Literal AI: Observability & Evaluation for RAG & LLMs. Debug, monitor, optimize performance & ensure production-ready AI apps.
-

AutoArena is an open-source tool that automates head-to-head evaluations using LLM judges to rank GenAI systems. Quickly and accurately generate leaderboards comparing different LLMs, RAG setups, or prompt variations—Fine-tune custom judges to fit your needs.
-

Call all LLM APIs using the OpenAI format. Use Bedrock, Azure, OpenAI, Cohere, Anthropic, Ollama, Sagemaker, HuggingFace, Replicate (100+ LLMs)