
Best AI2 WildBench Leaderboard Alternatives in 2025
-

LiveBench is an LLM benchmark with monthly new questions from diverse sources and objective answers for accurate scoring, currently featuring 18 tasks in 6 categories and more to come.
-

Launch AI products faster with no-code LLM evaluations. Compare 180+ models, craft prompts, and test confidently.
-

BenchLLM: Evaluate LLM responses, build test suites, automate evaluations. Enhance AI-driven systems with comprehensive performance assessments.
-

Web Bench is a new, open, and comprehensive benchmark dataset specifically designed to evaluate the performance of AI web browsing agents on complex, real-world tasks across a wide variety of live websites.
-

xbench: The AI benchmark tracking real-world utility and frontier capabilities. Get accurate, dynamic evaluation of AI agents with our dual-track system.
-

Explore The Berkeley Function Calling Leaderboard (also called The Berkeley Tool Calling Leaderboard) to see the LLM's ability to call functions (aka tools) accurately.
-

Choose the best AI agent for your needs with the Agent Leaderboard—unbiased, real-world performance insights across 14 benchmarks.
-

Deepchecks: The end-to-end platform for LLM evaluation. Systematically test, compare, & monitor your AI apps from dev to production. Reduce hallucinations & ship faster.
-

BenchX: Benchmark & improve AI agents. Track decisions, logs, & metrics. Integrate into CI/CD. Get actionable insights.
-

ZeroBench: The ultimate benchmark for multimodal models, testing visual reasoning, accuracy, and computational skills with 100 challenging questions and 334 subquestions.
-
Weights & Biases: The unified AI developer platform to build, evaluate, & manage ML, LLMs, & agents faster.
-

Real-time Klu.ai data powers this leaderboard for evaluating LLM providers, enabling selection of the optimal API and model for your needs.
-
Explore different Text Generation models by drafting messages and fine-tuning your responses.
-

Braintrust: The end-to-end platform to develop, test & monitor reliable AI applications. Get predictable, high-quality LLM results.
-
Evaluate Large Language Models easily with PromptBench. Assess performance, enhance model capabilities, and test robustness against adversarial prompts.
-

Companies of all sizes use Confident AI justify why their LLM deserves to be in production.
-

Geekbench AI is a cross-platform AI benchmark that uses real-world machine learning tasks to evaluate AI workload performance.
-

Your premier destination for comparing AI models worldwide. Discover, evaluate, and benchmark the latest advancements in artificial intelligence across diverse applications.
-

Huggingface’s Open LLM Leaderboard aims to foster open collaboration and transparency in the evaluation of language models.
-

The SEAL Leaderboards show that OpenAI’s GPT family of LLMs ranks first in three of the four initial domains it’s using to rank AI models, with Anthropic PBC’s popular Claude 3 Opus grabbing first place in the fourth category. Google LLC’s Gemini models also did well, ranking joint-first with the GPT models in a couple of the domains.
-

WizardLM-2 8x22B is Microsoft AI's most advanced Wizard model. It demonstrates highly competitive performance compared to leading proprietary models, and it consistently outperforms all existing state-of-the-art opensource models.
-

LLMWizard is an all-in-one AI platform that provides access to multiple advanced AI models through a single subscription. It offers features like custom AI assistants, PDF analysis, chatbot/assistant creation, and team collaboration tools.
-

Instantly compare the outputs of ChatGPT, Claude, and Gemini side by side using a single prompt. Perfect for researchers, content creators, and AI enthusiasts, our platform helps you choose the best language model for your needs, ensuring optimal results and efficiency.
-

Explore InternLM2, an AI tool with open-sourced models! Excel in long-context tasks, reasoning, math, code interpretation, and creative writing. Discover its versatile applications and strong tool utilization capabilities for research, application development, and chat interactions. Upgrade your AI landscape with InternLM2.
-
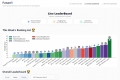
FutureX: Dynamically evaluate LLM agents' real-world predictive power for future events. Get uncontaminated insights into true AI intelligence.
-
Stax: Confidently ship LLM apps. Evaluate AI models & prompts against your unique criteria for data-driven insights. Build better AI, faster.
-
LangWatch provides an easy, open-source platform to improve and iterate on your current LLM pipelines, as well as mitigating risks such as jailbreaking, sensitive data leaks and hallucinations.
-

LightEval is a lightweight LLM evaluation suite that Hugging Face has been using internally with the recently released LLM data processing library datatrove and LLM training library nanotron.
-

Alpha Arena: The real-world benchmark for AI investment. Test AI models with actual capital in live financial markets to prove performance & manage risk.
-

Windows Agent Arena (WAA) is an open-source testing ground for AI agents in Windows. Empowers agents with diverse tasks, reduces evaluation time. Ideal for AI researchers and developers.