
What is ModelBench?
ModelBench 是一個一站式平台,讓您能更快地建構、測試和部署 AI 解決方案。無論您是產品經理、提示工程師還是開發人員,ModelBench 都能讓您的團隊輕鬆實驗、比較和優化大型語言模型 (LLM),無需繁瑣的編碼。
為什麼選擇 ModelBench?
節省時間:並排比較 180 多個 LLM,並在幾分鐘內找出效能最佳的模型和提示。
無需編碼的簡潔性:讓您的整個團隊都能參與實驗和迭代,無論其技術專長如何。
更快的部署:大幅縮短開發和測試時間,縮短產品上市時間。
主要功能?
✅ 並排比較 180 多個模型
同時測試和評估多個 LLM,以找到最符合您用例的模型。
✅ 設計和微調提示
設計、優化和測試提示,並從多個模型獲得即時回饋。
✅ 動態輸入以進行可擴展的測試
從 Google 試算表等工具導入數據集,並在無數場景中測試提示。
✅ 與人類或 AI 進行基準測試
使用 AI、人工審閱者或兩者混合進行評估,以獲得可靠的結果。
✅ 追蹤和重播 LLM 運行
監控互動、重播回應並偵測低品質輸出,無需編碼整合。
✅ 與您的團隊協作
無縫分享提示、結果和基準測試,以加快開發速度。
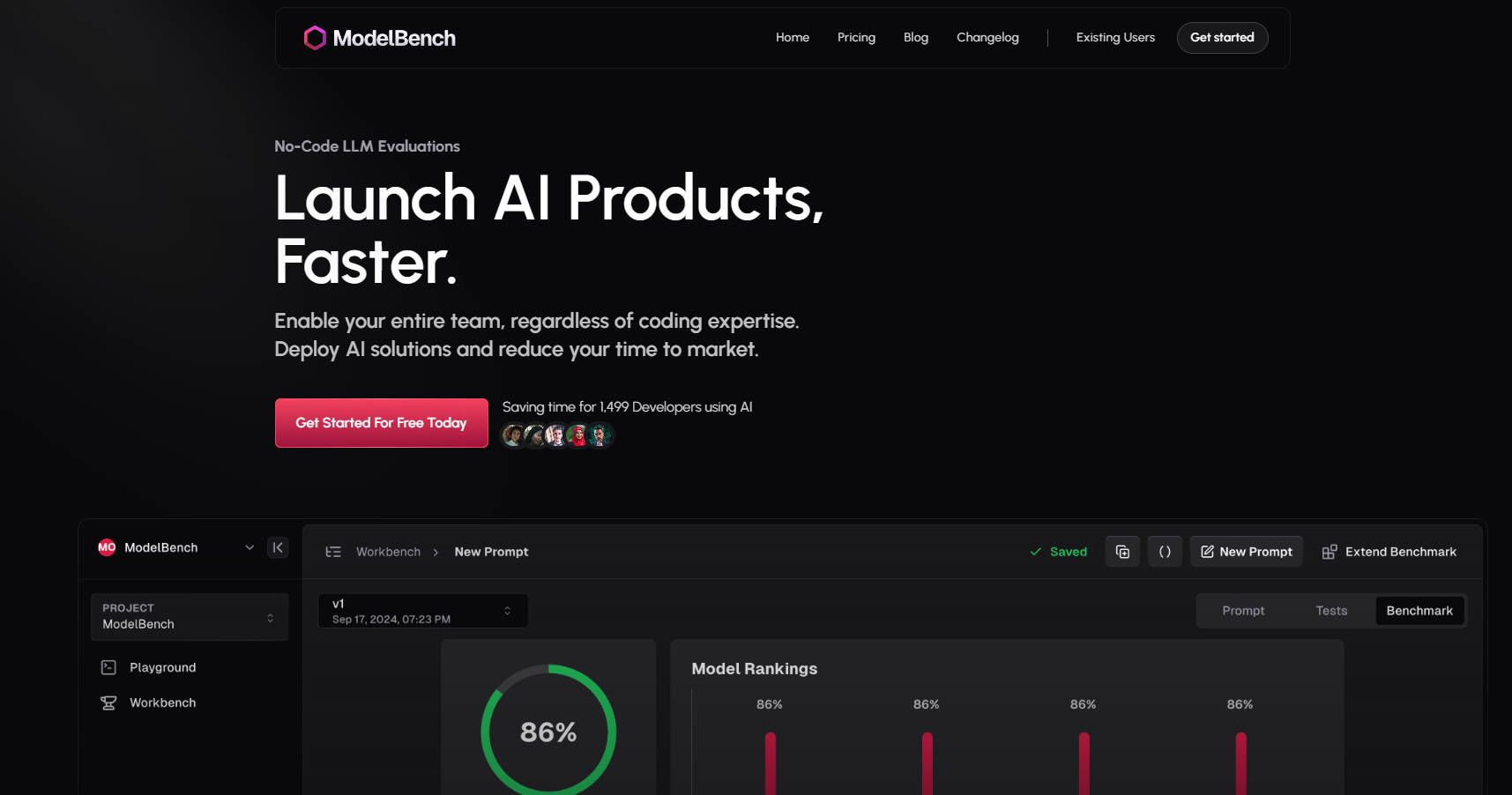
ModelBench 的運作方式
Playground(遊樂場):
即時比較 180 多個模型。
輕鬆測試提示並整合自訂工具。
Workbench(工作台):
將實驗轉換為結構化的基準測試。
使用動態輸入和版本控制,大規模測試提示。
Benchmarking(基準測試):
在多個模型上執行多輪測試。
分析結果以優化和改進您的提示。
誰適合使用 ModelBench?
產品經理:快速驗證 AI 解決方案並縮短產品上市時間。
提示工程師:微調提示並在多個模型上基準測試效能。
開發人員:在無需複雜編碼或框架的情況下實驗 LLM。
使用案例
電子商務聊天機器人:測試和優化多個 LLM 的客戶支援提示。
內容產生:比較模型以找到最適合產生高品質、符合品牌形象內容的模型。
AI 驅動的工具:為摘要、翻譯或情緒分析等任務基準測試 LLM。
立即開始
加入來自亞馬遜、Google 和 Twitch 等公司的 1,499 位開發人員和團隊,一起使用 ModelBench 節省時間。
More information on ModelBench
Launched
2024-05
Pricing Model
Free Trial
Starting Price
49 $ Monthly
Global Rank
7783759
Follow
Month Visit
<5k
Tech used
Google Tag Manager,Amazon AWS CloudFront,Google Fonts
Top 5 Countries
54.29%
29.54%
16.16%
India
United States
United Kingdom
Traffic Sources
31.14%
1.68%
0.13%
24.42%
20.47%
21.7%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 25, 2025)
ModelBench was manually vetted by our editorial team and was first featured on 2025-01-21.
Related Searches
ModelBench 替代方案
更多 替代方案-
-

-

-

-

WildBench 是一個先進的基準測試工具,用於評估 LLM 在各種真實世界任務中的表現。對於那些希望提升 AI 效能並了解模型在實際情境中的局限性的人來說,它是必不可少的工具。