
What is Belebele?
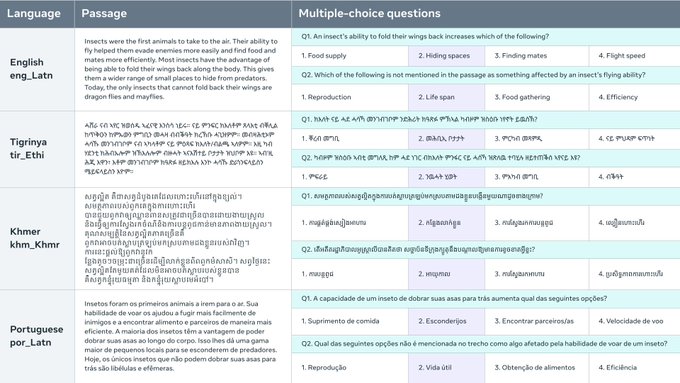
The Belebele Benchmark is a machine reading comprehension (MRC) dataset that consists of multiple-choice questions in 122 different language variants. This dataset allows for the evaluation of language models in high-, medium-, and low-resource languages. Each question is linked to a short passage from the FLORES-200 dataset and has four multiple-choice answers, with one correct answer. The dataset is carefully curated to test the generalizable language comprehension of models and enables direct comparison of performance across languages. The Belebele Benchmark provides a valuable tool for evaluating and analyzing the multilingual abilities of AI language models.
Key Features:
Multiple-choice MRC dataset: The Belebele Benchmark offers a wide range of multiple-choice questions in 122 language variants, allowing for comprehensive evaluation of language models.
High-quality annotations: The human annotation procedure ensures the creation of questions that effectively discriminate between different levels of language comprehension, enhancing the quality of evaluation.
Parallel dataset for direct comparison: Being fully parallel, the Belebele Benchmark enables direct performance comparison of language models across all languages, providing valuable insights into multilingual abilities.
Use Cases:
Evaluating language models: The Belebele Benchmark serves as a valuable resource for evaluating the performance of language models in various languages, from high-resource to low-resource settings.
Analyzing multilingual abilities: Researchers and developers can utilize the dataset to analyze and understand the multilingual capabilities of AI language models, enabling advancements in natural language processing systems.
Cross-lingual evaluation: The parallel nature of the dataset allows for cross-lingual evaluation, where models can be tested on passages and questions in different languages, providing a comprehensive assessment of their performance.
Conclusion:
The Belebele Benchmark offers a comprehensive and diverse dataset for evaluating language models in multiple languages. With its multiple-choice questions and carefully curated annotations, the dataset enables accurate assessment of language comprehension capabilities. Researchers and developers can leverage the Belebele Benchmark to analyze and enhance the multilingual abilities of AI language models, leading to advancements in natural language understanding and processing.
More information on Belebele
Launched
2023
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Belebele was manually vetted by our editorial team and was first featured on 2023-09-06.
Related Searches
Belebele Alternatives
Load more Alternatives-

-

-

WildBench is an advanced benchmarking tool that evaluates LLMs on a diverse set of real-world tasks. It's essential for those looking to enhance AI performance and understand model limitations in practical scenarios.
-

-

Launch AI products faster with no-code LLM evaluations. Compare 180+ models, craft prompts, and test confidently.