
What is Belebele?
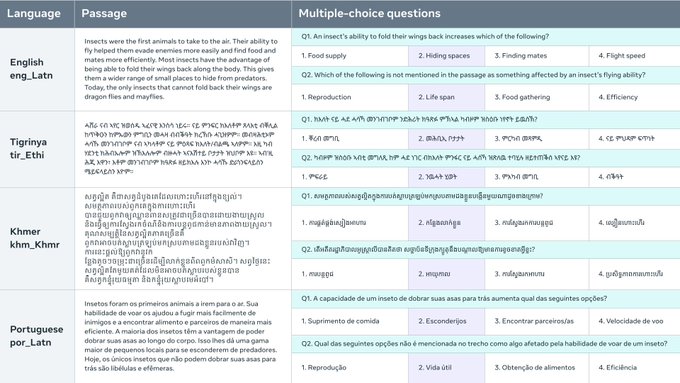
Belebele Benchmarkは、122種類の言語バリエーションで多肢選択問題で構成された機械読解(MRC)データセットです。このデータセットにより、言語モデルを高、中、低リソース言語で評価することが可能になります。各質問はFLORES-200データセットからの短い文章にリンクされており、4つの多肢選択の回答があり、そのうち1つが正解です。このデータセットはモデルの一般化可能な言語理解力をテストするために慎重に作成されており、言語間でのパフォーマンスを直接比較することができます。Belebele Benchmarkは、AI言語モデルの多言語能力を評価および分析するための貴重なツールを提供します。
主な機能:
多肢選択MRCデータセット: Belebele Benchmarkは、122の言語バリエーションでさまざまな多肢選択問題を提供しており、言語モデルの包括的な評価を可能にします。
高品質の注釈: 人間の注釈付け手順により、さまざまなレベルの言語理解力を効果的に区別する質問を作成し、評価の質を向上させます。
直接比較するための並列データセット: Belebele Benchmarkは完全な並列データセットであるため、言語モデルのパフォーマンスをすべての言語で直接比較することができ、多言語能力に関する貴重な洞察を得ることができます。
ユースケース:
言語モデルの評価: Belebele Benchmarkは、高リソースから低リソースの設定まで、さまざまな言語で言語モデルのパフォーマンスを評価するための貴重なリソースとして機能します。
多言語能力の分析: 研究者や開発者は、データセットを利用してAI言語モデルの多言語能力を分析および理解し、自然言語処理システムの進歩を可能にします。
相互言語評価: データセットの並列性は、相互言語評価を可能にし、モデルがさまざまな言語の文章と質問でテストされ、パフォーマンスに関する包括的な評価が提供されます。
結論:
Belebele Benchmarkは、複数の言語で言語モデルを評価するための包括的で多様なデータセットを提供します。多肢選択問題と慎重に作成された注釈により、このデータセットは言語理解能力の正確な評価を可能にします。研究者や開発者は、Belebele Benchmarkを活用してAI言語モデルの多言語能力を分析および強化し、自然言語の理解と処理における進歩につながります。
More information on Belebele
Launched
2023
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Belebele was manually vetted by our editorial team and was first featured on 2023-09-06.
Related Searches
Belebele 代替ソフト
もっと見る 代替ソフト-

-

-

WildBenchは、現実世界のさまざまなタスクでLLMを評価する、高度なベンチマークツールです。AIのパフォーマンスを向上させ、実際のシナリオにおけるモデルの限界を理解したいと考えている人にとって不可欠です。
-

-

ノーコードのLLM評価で、AI製品をより迅速にローンチしましょう。180種類以上のモデルを比較し、プロンプトを作成し、自信を持ってテストできます。