
What is Belebele?
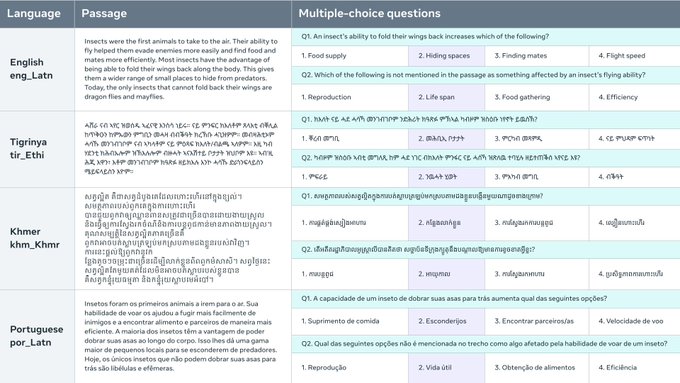
Набор данных Belebele Benchmark представляет собой набор данных для машинного понимания текста (MRC), который состоит из вопросов с несколькими вариантами ответа на 122 различных языковых вариантах. Этот набор данных предназначен для оценки языковых моделей на языках с высоким, средним и низким уровнем ресурсов. Каждый вопрос связан с коротким отрывком из набора данных FLORES-200 и имеет четыре варианта ответа с несколькими вариантами, из которых один правильный. Набор данных тщательно отобран для проверки общего понимания языка моделями и позволяет напрямую сравнивать производительность на разных языках. Набор данных Belebele Benchmark предоставляет ценный инструмент для оценки и анализа многоязычных возможностей языковых моделей ИИ.
Ключевые возможности:
Набор данных MRC с несколькими вариантами ответа: Belebele Benchmark предлагает широкий спектр вопросов с несколькими вариантами ответа на 122 языковых вариантах, что позволяет всесторонне оценивать языковые модели.
Аннотации высокого качества: процедура аннотации человеком гарантирует создание вопросов, которые эффективно различают различные уровни понимания языка, повышая качество оценки.
Параллельный набор данных для прямого сравнения: будучи полностью параллельным, Belebele Benchmark позволяет напрямую сравнивать производительность языковых моделей на всех языках, предоставляя ценную информацию о многоязычных возможностях.
Варианты использования:
Оценка языковых моделей: Belebele Benchmark служит ценным ресурсом для оценки производительности языковых моделей на разных языках, от языков с высоким уровнем ресурсов до языков с низким уровнем ресурсов.
Анализ многоязычных возможностей: исследователи и разработчики могут использовать набор данных для анализа и понимания многоязычных возможностей языковых моделей ИИ, что позволяет совершенствовать системы обработки естественного языка.
Межъязыковая оценка: параллельная природа набора данных позволяет проводить межъязыковую оценку, при которой модели могут тестироваться на отрывках и вопросах на разных языках, обеспечивая всестороннюю оценку их производительности.
Заключение:
Набор данных Belebele Benchmark предлагает комплексный и разнообразный набор данных для оценки языковых моделей на нескольких языках. Благодаря вопросам с несколькими вариантами ответа и тщательно подобранным аннотациям набор данных позволяет точно оценить возможности понимания языка. Исследователи и разработчики могут использовать набор данных Belebele Benchmark для анализа и улучшения многоязычных возможностей языковых моделей ИИ, что приведет к прогрессу в области понимания и обработки естественного языка.
More information on Belebele
Launched
2023
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Belebele was manually vetted by our editorial team and was first featured on 2023-09-06.
Related Searches
Belebele Альтернативи
Больше Альтернативи-

-

-

WildBench - это передовой инструмент для бенчмаркинга, который оценивает большие языковые модели (LLM) на разнообразном наборе реальных задач. Он незаменим для тех, кто стремится повысить производительность ИИ и понять ограничения модели в практических сценариях.
-

-

Запускайте продукты на основе ИИ быстрее с помощью бескликовой оценки больших языковых моделей. Сравнивайте более 180 моделей, создавайте запросы и тестируйте с уверенностью.