
What is Belebele?
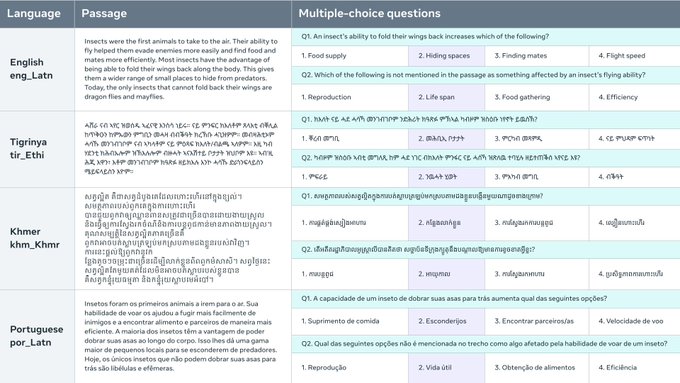
Belebele Benchmark 是一種機器閱讀理解(MRC)資料集,包含 122 種不同語言變體的多選題。此資料集可評估語言模型在高、中、低資源語言中的表現。每個問題連結到 FLORES-200 資料集中的一段短文,並有四個多選題答案,其中一個是正確答案。此資料集經過仔細策劃,用於測試模型的通用語言理解力,並能直接比較不同語言的表現。Belebele Benchmark 提供了一個有價值的工具,用於評估和分析 AI 語言模型的多語言能力。
主要特色:
多選題 MRC 資料集:Belebele Benchmark 提供 122 種語言變體的各種多選題,可全面評估語言模型。
高品質註解:人工註解程序可確保創造出有效區分不同語言理解層級的問題,進而提升評估品質。
平行資料集,可直接比較:Belebele Benchmark 完全平行,可直接比較所有語言中語言模型的表現,提供多語言能力的寶貴見解。
使用案例:
評估語言模型:Belebele Benchmark 是評估語言模型在各種語言中表現的寶貴資源,從高資源到低資源設定皆可使用。
分析多語言能力:研究人員和開發人員可利用此資料集分析和了解 AI 語言模型的多語言能力,促進自然語言處理系統的進步。
跨語言評估:資料集的平行特性允許跨語言評估,模型可在不同語言的文章和問題上接受測試,提供全面評估其表現。
結論:
Belebele Benchmark 提供一個全面且多樣的資料集,用於評估多種語言中的語言模型。此資料集以其多選題和仔細策劃的註解,能準確評估語言理解能力。研究人員和開發人員可利用 Belebele Benchmark 分析和增強 AI 語言模型的多語言能力,進而促進自然語言理解和處理的進步。
More information on Belebele
Launched
2023
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Belebele was manually vetted by our editorial team and was first featured on 2023-09-06.
Related Searches
Belebele 替代方案
更多 替代方案-

-

-

WildBench 是一個先進的基準測試工具,用於評估 LLM 在各種真實世界任務中的表現。對於那些希望提升 AI 效能並了解模型在實際情境中的局限性的人來說,它是必不可少的工具。
-

-
