
What is Belebele?
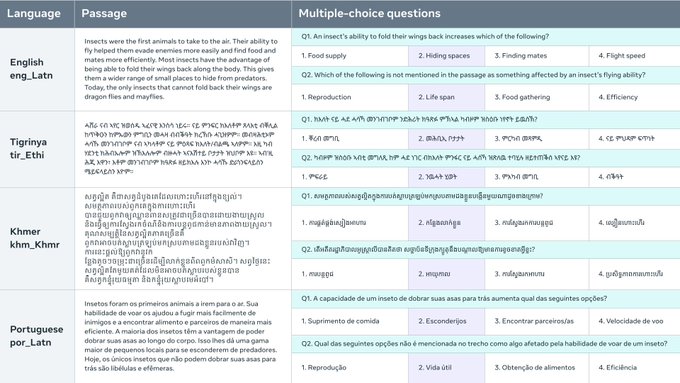
El Belebele Benchmark es un conjunto de datos de comprensión lectora de máquina (MRC) que consta de preguntas de opción múltiple en 122 variantes idiomáticas. Este conjunto de datos permite evaluar modelos de lenguaje en idiomas con muchos, pocos y medianos recursos. Cada pregunta está vinculada a un pasaje breve del conjunto de datos FLORES-200 y tiene cuatro respuestas de opción múltiple, con una respuesta correcta. El conjunto de datos se selecciona cuidadosamente para poner a prueba la comprensión del lenguaje generalizable de los modelos y permite la comparación directa del rendimiento en varios idiomas. El Belebele Benchmark proporciona una valiosa herramienta para evaluar y analizar las capacidades multilingües de los modelos de lenguaje de la IA.
Características principales:
Conjunto de datos de MRC de opción múltiple: El Belebele Benchmark ofrece una amplia gama de preguntas de opción múltiple en 122 variantes idiomáticas, lo que permite una evaluación integral de los modelos de lenguaje.
Anotaciones de alta calidad: El procedimiento de anotación humana garantiza la creación de preguntas que discriminan eficazmente entre diferentes niveles de comprensión del lenguaje, lo que mejora la calidad de la evaluación.
Conjunto de datos paralelo para comparación directa: Al ser totalmente paralelo, el Belebele Benchmark permite una comparación directa del rendimiento de los modelos de lenguaje en todos los idiomas, lo que proporciona información valiosa sobre las capacidades multilingües.
Casos de uso:
Evaluación de modelos de lenguaje: El Belebele Benchmark sirve como un valioso recurso para evaluar el rendimiento de los modelos de lenguaje en varios idiomas, desde aquellos con muchos recursos hasta aquellos con pocos.
Análisis de capacidades multilingües: Los investigadores y desarrolladores pueden utilizar el conjunto de datos para analizar y comprender las capacidades multilingües de los modelos de lenguaje de la IA, lo que permite avances en los sistemas de procesamiento del lenguaje natural.
Evaluación interlingüística: La naturaleza paralela del conjunto de datos permite la evaluación interlingüística, donde los modelos se pueden poner a prueba en pasajes y preguntas en diferentes idiomas, lo que proporciona una evaluación integral de su rendimiento.
Conclusión:
El Belebele Benchmark ofrece un conjunto de datos completo y diverso para evaluar modelos de lenguaje en varios idiomas. Con sus preguntas de opción múltiple y anotaciones cuidadosamente seleccionadas, el conjunto de datos permite una evaluación precisa de las capacidades de comprensión del lenguaje. Los investigadores y desarrolladores pueden aprovechar el Belebele Benchmark para analizar y mejorar las capacidades multilingües de los modelos de lenguaje de la IA, lo que lleva a avances en la comprensión y el procesamiento del lenguaje natural.
More information on Belebele
Launched
2023
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Belebele was manually vetted by our editorial team and was first featured on 2023-09-06.
Related Searches
Belebele Alternativas
Más Alternativas-

-

-

WildBench es una herramienta de evaluación avanzada que evalúa los LLM en un conjunto diverso de tareas del mundo real. Es esencial para aquellos que buscan mejorar el rendimiento de la IA y comprender las limitaciones del modelo en escenarios prácticos.
-

-

Lanza productos de IA más rápido con evaluaciones LLM sin código. Compara más de 180 modelos, crea prompts y prueba con confianza.