
What is Belebele?
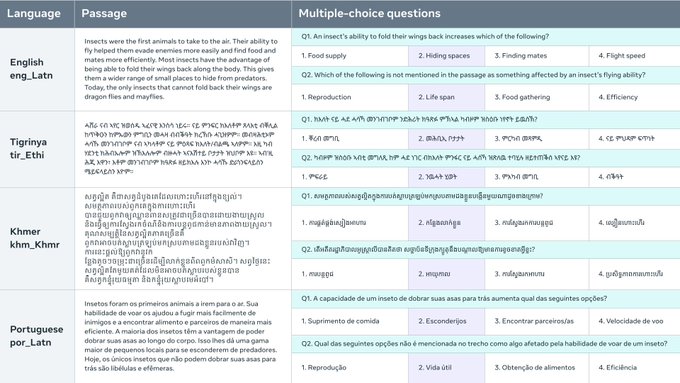
贝莱贝勒基准测试是一种机器阅读理解 (MRC) 数据集,包含 122 种不同语言变体的多项选择题。此数据集允许对高、中、低资源语言中的语言模型进行评估。每个问题都与 FLORES-200 数据集中的一个短篇章相关联,并有四个多项选择答案,其中一个答案是正确的。该数据集经过精心策划,用于测试模型的泛化语言理解能力,并支持直接比较跨语言的性能。贝莱贝勒基准测试为评估和分析人工智能语言模型的多语言能力提供了一个有价值的工具。
主要功能:
多项选择 MRC 数据集:贝莱贝勒基准测试提供了 122 种语言变体的各种多项选择题,可全面评估语言模型。
高质量注释:人工注释过程确保创建的问题可以有效地区分不同级别的语言理解,从而提高评估的质量。
直接比较的并行数据集:贝莱贝勒基准测试完全并行,支持直接比较跨所有语言的语言模型性能,从而提供多语言能力的宝贵见解。
用例:
评估语言模型:贝莱贝勒基准测试是评估高资源到低资源设置下各种语言中语言模型性能的宝贵资源。
分析多语言能力:研究人员和开发人员可以利用该数据集分析和理解人工智能语言模型的多语言能力,从而推动自然语言处理系统的进步。
跨语言评估:该数据集的并行特性允许进行跨语言评估,其中可以在不同语言的段落和问题上测试模型,从而全面评估其性能。
结论:
贝莱贝勒基准测试提供了一个全面且多样化的数据集,用于评估多语言中的语言模型。凭借其多项选择题和精心策划的注释,该数据集能够准确评估语言理解能力。研究人员和开发人员可以利用贝莱贝勒基准测试来分析和增强人工智能语言模型的多语言能力,从而推动自然语言理解和处理的进步。
More information on Belebele
Launched
2023
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Belebele was manually vetted by our editorial team and was first featured on 2023-09-06.
Related Searches
Belebele 替代方案
更多 替代方案-

-

-

WildBench 是一款先进的基准测试工具,用于评估大型语言模型 (LLM) 在各种现实世界任务中的表现。对于那些希望提高 AI 性能并了解模型在实际场景中的局限性的用户来说,它至关重要。
-

-
