
What is Belebele?
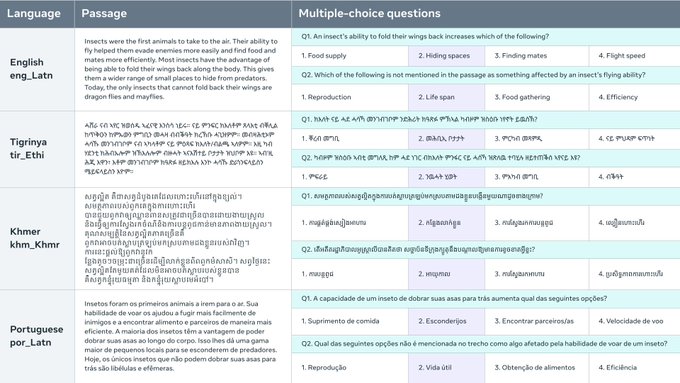
벨레벨 벤치마크는 122개의 다양한 언어 변종으로 된 객관식 질문으로 구성된 기계 독해 이해(MRC) 데이터셋입니다. 이 데이터셋은 고자원, 중자원, 저자원 언어에서 언어 모델의 평가를 가능하게 합니다. 각 질문은 FLORES-200 데이터셋의 짧은 패시지와 연결되어 있으며, 하나의 정답과 함께 4개의 객관식 답변을 제공합니다. 이 데이터셋은 모델의 일반화된 언어 이해력을 시험하기 위해 세심하게 큐레이팅되었고, 언어 간 성능을 직접 비교할 수 있습니다. 벨레벨 벤치마크는 AI 언어 모델의 다국어 능력을 평가하고 분석하는 데 가치 있는 도구를 제공합니다.
주요 특징:
객관식 MRC 데이터셋: 벨레벨 벤치마크는 122개의 언어 변종으로 다양한 객관식 질문을 제공하여 언어 모델의 포괄적인 평가를 가능하게 합니다.
고품질 주석: 인간 주석 절차를 통해 언어 이해의 다양한 수준을 효과적으로 구분하는 질문을 생성하여 평가의 질을 향상시킵니다.
직접 비교를 위한 병렬 데이터셋: 완전히 병렬화된 벨레벨 벤치마크는 모든 언어에서 언어 모델의 성능을 직접 비교하여 다국어 능력에 대한 가치 있는 통찰력을 제공합니다.
사용 사례:
언어 모델 평가: 벨레벨 벤치마크는 고자원부터 저자원 설정까지 다양한 언어에서 언어 모델의 성능을 평가하는 데 귀중한 리소스 역할을 합니다.
다국어 능력 분석: 연구자와 개발자는 이 데이터셋을 활용하여 AI 언어 모델의 다국어 능력을 분석하고 이해하여 자연어 처리 시스템을 발전시킬 수 있습니다.
언어 간 평가: 데이터셋의 병렬적 특성을 통해 모델을 다양한 언어의 패시지와 질문에 대해 테스트할 수 있는 언어 간 평가가 가능하여 성능을 포괄적으로 평가할 수 있습니다.
결론:
벨레벨 벤치마크는 다국어에서 언어 모델을 평가하기 위한 포괄적이고 다양한 데이터셋을 제공합니다. 객관식 질문과 신중하게 큐레이팅된 주석을 통해 이 데이터셋은 언어 이해 능력을 정확하게 평가할 수 있도록 합니다. 연구자와 개발자는 벨레벨 벤치마크를 활용하여 AI 언어 모델의 다국어 능력을 분석하고 향상시켜 자연어 이해 및 처리를 발전시킬 수 있습니다.
More information on Belebele
Launched
2023
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Belebele was manually vetted by our editorial team and was first featured on 2023-09-06.
Related Searches
Belebele 대체품
더보기 대체품-

-

-

WildBench는 다양한 실제 작업 세트에서 LLM을 평가하는 고급 벤치마킹 도구입니다. 실제 시나리오에서 AI 성능을 향상시키고 모델의 한계를 이해하려는 사람들에게 필수적입니다.
-

-

노코드 LLM 평가로 AI 제품 출시 속도를 높이세요. 180개 이상의 모델을 비교하고, 프롬프트를 만들고, 자신 있게 테스트하세요.