
What is Belebele?
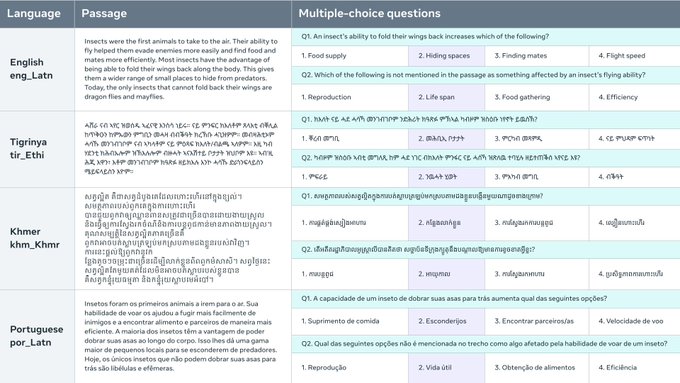
Le Benchmark Belebele est un ensemble de données de compréhension de la lecture par machine (MRC) qui se compose de questions à choix multiple dans 122 variantes de langues différentes. Cet ensemble de données permet d'évaluer les modèles linguistiques dans des langues à ressources élevées, moyennes et faibles. Chaque question est liée à un court passage de l'ensemble de données FLORES-200 et comporte quatre réponses à choix multiple, avec une seule réponse correcte. L'ensemble de données est soigneusement organisé pour tester la compréhension linguistique généralisable des modèles et permet une comparaison directe des performances entre les langues. Le Benchmark Belebele fournit un outil précieux pour évaluer et analyser les capacités multilingues des modèles linguistiques d'IA.
Caractéristiques principales :
Ensemble de données MRC à choix multiple : le Benchmark Belebele offre une large gamme de questions à choix multiple dans 122 variantes de langues, permettant une évaluation complète des modèles linguistiques.
Annotations de haute qualité : la procédure d'annotation humaine garantit la création de questions qui distinguent efficacement les différents niveaux de compréhension linguistique, améliorant la qualité de l'évaluation.
Ensemble de données parallèle pour une comparaison directe : étant entièrement parallèle, le Benchmark Belebele permet une comparaison directe des performances des modèles linguistiques dans toutes les langues, fournissant des informations précieuses sur les capacités multilingues.
Cas d'utilisation :
Évaluer les modèles linguistiques : le Benchmark Belebele sert de ressource précieuse pour évaluer les performances des modèles linguistiques dans diverses langues, des environnements à ressources élevées aux environnements à faibles ressources.
Analyser les capacités multilingues : les chercheurs et les développeurs peuvent utiliser l'ensemble de données pour analyser et comprendre les capacités multilingues des modèles linguistiques d'IA, permettant des avancées dans les systèmes de traitement du langage naturel.
Évaluation interlinguistique : la nature parallèle de l'ensemble de données permet une évaluation interlinguistique, où les modèles peuvent être testés sur des passages et des questions dans différentes langues, fournissant une évaluation complète de leurs performances.
Conclusion :
Le Benchmark Belebele offre un ensemble de données complet et diversifié pour évaluer les modèles linguistiques dans plusieurs langues. Avec ses questions à choix multiple et ses annotations soigneusement organisées, l'ensemble de données permet une évaluation précise des capacités de compréhension linguistique. Les chercheurs et les développeurs peuvent exploiter le Benchmark Belebele pour analyser et améliorer les capacités multilingues des modèles linguistiques d'IA, conduisant à des avancées dans la compréhension et le traitement du langage naturel.
More information on Belebele
Launched
2023
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Belebele was manually vetted by our editorial team and was first featured on 2023-09-06.
Related Searches
Belebele Alternatives
Plus Alternatives-

-

-

WildBench est un outil de benchmark avancé qui évalue les LLM sur un ensemble diversifié de tâches du monde réel. Il est essentiel pour ceux qui cherchent à améliorer les performances de l'IA et à comprendre les limites des modèles dans des scénarios pratiques.
-

-

Lancez plus rapidement vos produits d'IA grâce aux évaluations LLM sans code. Comparez plus de 180 modèles, concevez des invites et testez en toute confiance.