
What is AI2 WildBench Leaderboard?
WildBenchは、大規模言語モデル(LLM)の能力を評価するために設計された最先端のベンチマークツールです。LLMを、現実世界のユーザーとのやり取りを模倣した、多様な課題のセットと対決させることで、その能力を評価します。この革新的なプラットフォームは、LLMのパフォーマンスが、人間の言語とコンテキストの微妙な理解に基づいて評価されることを保証し、LLMの長所と短所に関する貴重な洞察を提供します。
主な機能
現実世界のタスクシミュレーション: WildBenchは、人間とGPTのやり取りの膨大なデータセットであるWildChatから収集されたタスクを使用しており、評価が実際のユーザーシナリオを反映することを保証します。
多様なタスクカテゴリ: 12種類のタスクカテゴリを持つWildBenchは、幅広い現実世界のユーザーシナリオを網羅し、従来のベンチマークでは実現できなかったバランスのとれた分布を維持しています。
包括的な注釈: 各タスクには、二次タスクタイプやユーザーインテントなどの詳細な注釈が含まれており、応答評価のためのより深いレベルの洞察を提供します。
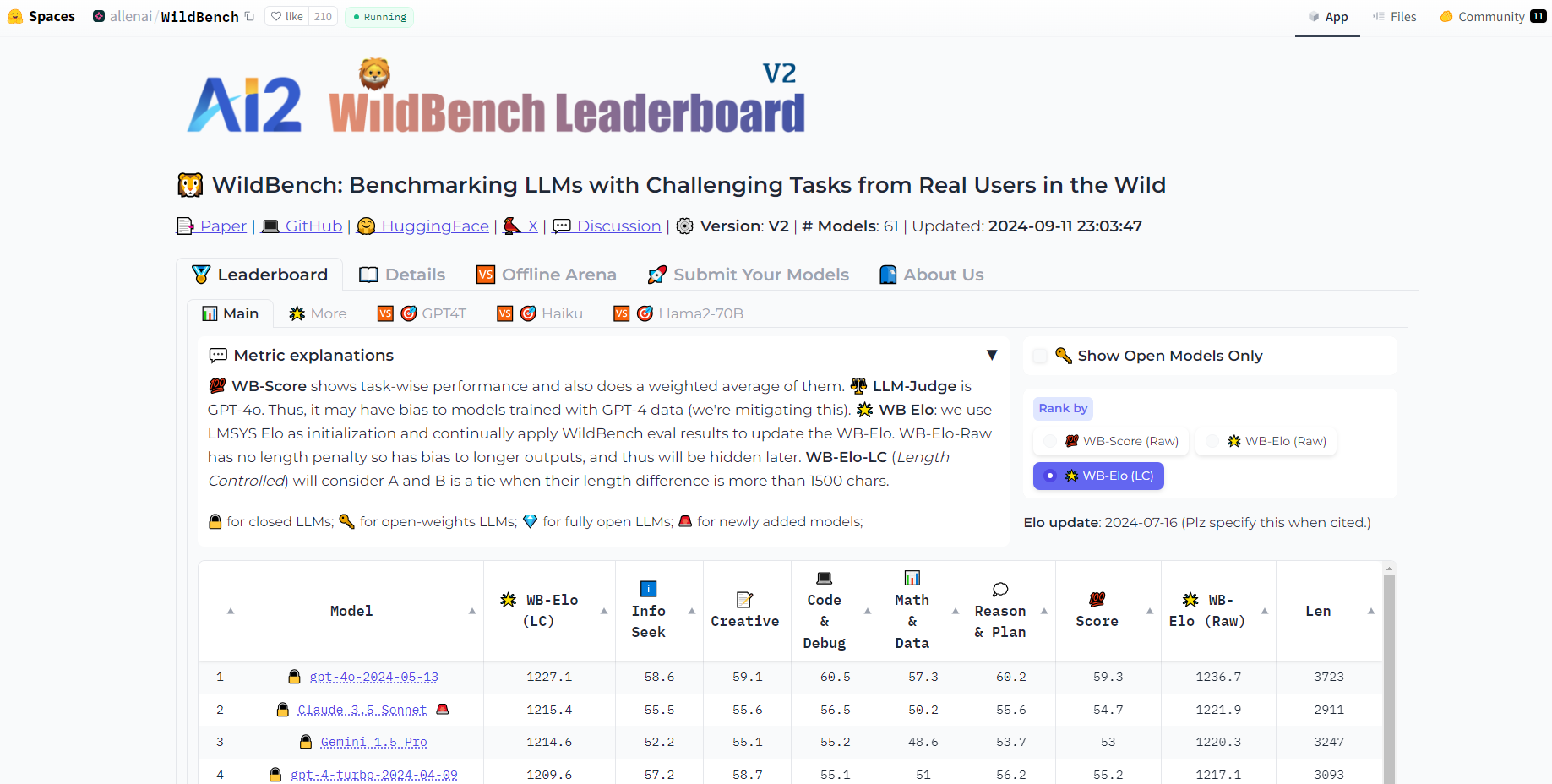
革新的な評価指標: WildBenchは、チェックリストベースの採点システム、個々のモデル評価のためのWBスコア、モデル間の比較分析のためのWB報酬を採用しています。
長さバイアスの軽減: WildBenchは、公平な評価を保証するために、LLMの審査員が長い応答を好む傾向に対抗する、カスタマイズ可能な長さペナルティ方法を導入しました。
ユースケース
モデル開発者: WildBenchの包括的な評価を通じてLLMの弱点を特定することで、LLMのパフォーマンスを向上させます。
AI研究者: 現実世界のタスクの複雑さに直面した際のLLMの能力に関する新しい洞察を得て、将来の研究の方向性を示します。
エンタープライズソリューション: 企業はWildBenchを使用して、カスタマーサービス、コンテンツ作成、その他のビジネスアプリケーションに最も適したLLMを選択できます。
結論
WildBenchは、現実的で微妙な評価プラットフォームを提供することで、AI言語モデルの評価方法に革命を起こしています。その実用的な影響は業界全体に及び、より有能で信頼性の高いAIソリューションの開発を可能にします。現実世界の課題と最先端のAIが融合するWildBenchで、AIの真の可能性を発見しましょう。
More information on AI2 WildBench Leaderboard
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
AI2 WildBench Leaderboard was manually vetted by our editorial team and was first featured on 2024-09-14.
Related Searches
AI2 WildBench Leaderboard 代替ソフト
もっと見る 代替ソフト-

-

ノーコードのLLM評価で、AI製品をより迅速にローンチしましょう。180種類以上のモデルを比較し、プロンプトを作成し、自信を持ってテストできます。
-

BenchLLM: LLMレスポンスを評価し、テストスイートを構築し、評価を自動化します。包括的なパフォーマンス評価により、AI駆動システムを強化します。
-

-
