
What is AI2 WildBench Leaderboard?
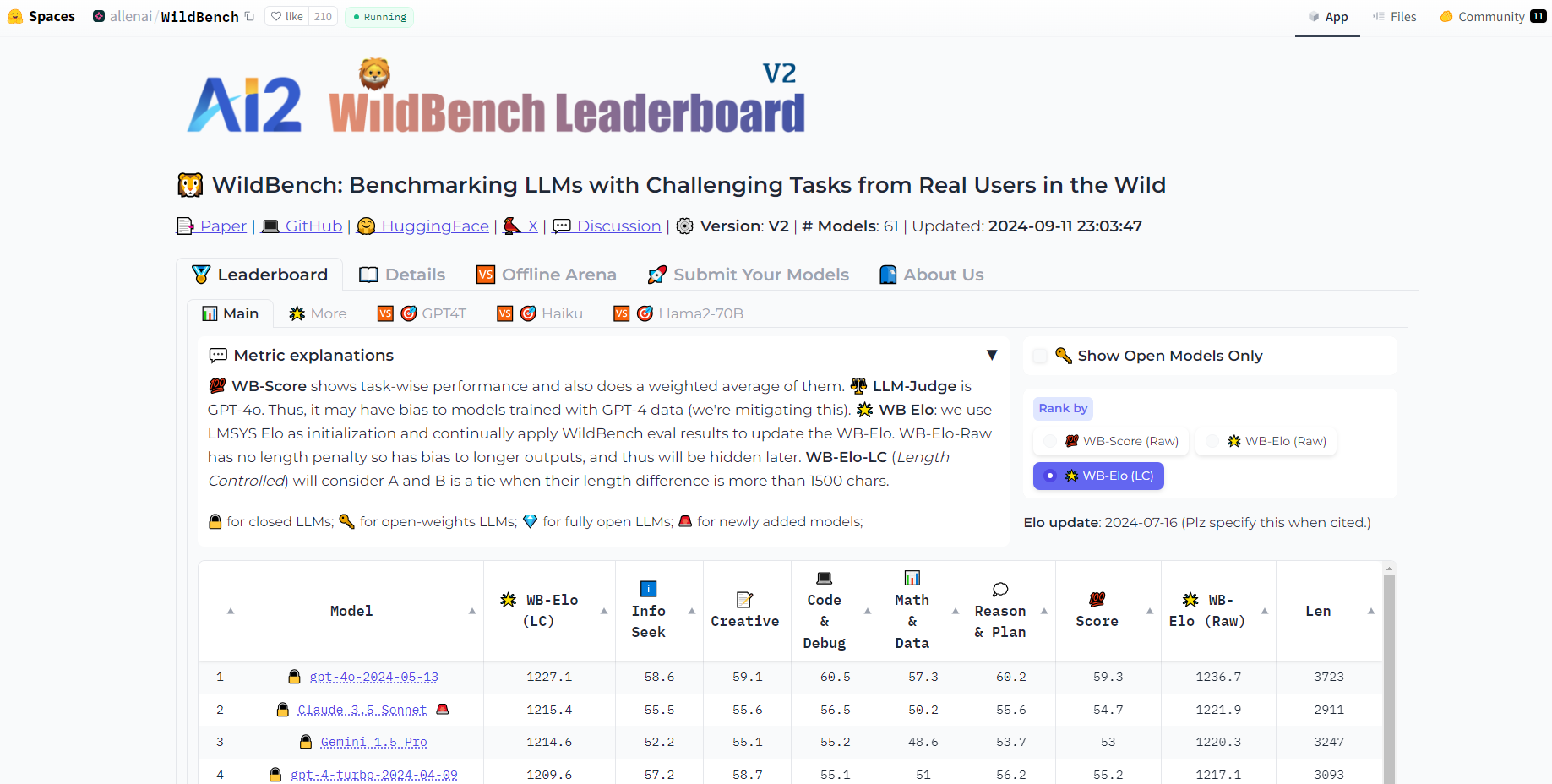
WildBench 是一款尖端的基准测试工具,旨在通过将大型语言模型 (LLM) 与模拟真实世界用户交互的各种具有挑战性的任务进行比较,来评估其能力。这个创新的平台确保了对 LLM 的性能评估基于对人类语言和语境的细致理解,从而为其优缺点提供了宝贵的见解。
主要功能
真实世界任务模拟:WildBench 使用从 WildChat 收集的任务,WildChat 是一个庞大的人机 GPT 交互数据集,确保评估反映真实的用例。
多样化的任务类别:WildBench 包含 12 类任务,涵盖了各种真实用户场景,保持着传统基准无法比拟的均衡分布。
全面的注释:每个任务都包含详细的注释,例如次要任务类型和用户意图,为响应评估提供更深入的洞察。
创新的评估指标:WildBench 采用基于清单的评分系统,单个模型评估使用 WB 分数,模型之间比较分析使用 WB 奖励。
长度偏差缓解:为了确保公平的评估,WildBench 引入了一种可定制的长度惩罚方法,以抵消 LLM 评委倾向于偏爱更长响应的倾向。
用例
模型开发人员:通过 WildBench 的全面评估,发现 LLM 的弱点,从而提高其性能。
人工智能研究人员:在面对现实世界任务的复杂性时,获得对 LLM 能力的新见解,为未来的研究方向提供参考。
企业解决方案:企业可以使用 WildBench 为客户服务、内容创作和其他商业应用选择最合适的 LLM。
结论
WildBench 通过提供一个现实且细致入微的评估平台,彻底改变了我们评估人工智能语言模型的方式。其实际影响遍及各个行业,促进了更强大、更可靠的人工智能解决方案的开发。使用 WildBench 探索人工智能的真正潜力 - 现实世界的挑战与尖端人工智能相遇的地方。
More information on AI2 WildBench Leaderboard
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
AI2 WildBench Leaderboard was manually vetted by our editorial team and was first featured on 2024-09-14.
Related Searches




