
What is AI2 WildBench Leaderboard?
WildBench 是一款尖端的基準測試工具,旨在透過讓大型語言模型 (LLM) 面對一系列模擬真實世界使用者互動的挑戰性任務,來評估其能力。這個創新的平台確保 LLM 的效能評估建立在對人類語言和語境的細膩理解之上,提供寶貴的見解,讓您了解其優勢和劣勢。
主要功能
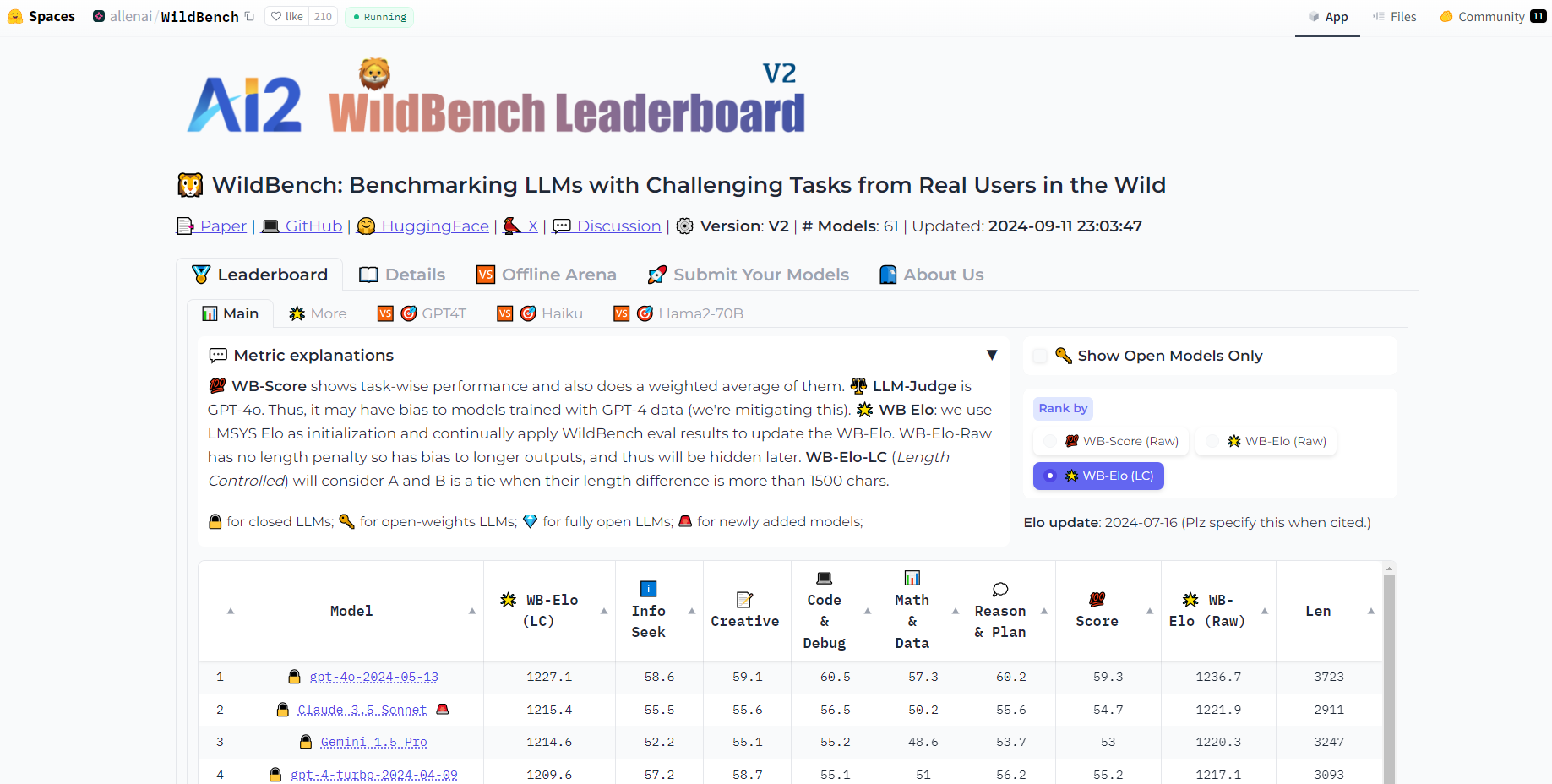
真實世界任務模擬:WildBench 使用從 WildChat 收集的任務,WildChat 是一個龐大的人類與 GPT 互動資料集,確保評估反映真正的使用者情境。
多樣化的任務類別:WildBench 包含 12 類任務,涵蓋各種真實使用者情境,維持傳統基準測試無法比擬的平衡分配。
全面的註解:每個任務都包含詳細的註解,例如次要任務類型和使用者意圖,為回應評估提供更深入的見解。
創新的評估指標:WildBench 採用清單式評分系統,針對個別模型評估使用 WB 分數,並使用 WB 獎勵進行模型之間的比較分析。
長度偏差緩解:為了確保公平的評估,WildBench 引入了可自訂的長度懲罰方法,以抵消 LLM 評估者偏好較長回應的倾向。
用例
模型開發人員:透過 WildBench 的全面評估,找出 LLM 的弱點,以提升其效能。
AI 研究人員:在面對真實世界任務的複雜性時,深入了解 LLM 的能力,為未來的研究方向提供資訊。
企業解決方案:企業可以使用 WildBench 選擇最適合客戶服務、內容創作和其他業務應用程式的 LLM。
結論
WildBench 正在徹底改變我們評估 AI 語言模型的方式,提供一個真實且細膩的評估平台。其實際影響遍及各行各業,促進更強大、更可靠的 AI 解決方案的發展。透過 WildBench 探索 AI 的真正潛力,讓真實世界的挑戰與尖端的 AI 相遇。
More information on AI2 WildBench Leaderboard
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
AI2 WildBench Leaderboard was manually vetted by our editorial team and was first featured on 2024-09-14.
Related Searches




