
What is AI2 WildBench Leaderboard?
WildBench는 대규모 언어 모델(LLM)의 능력을 평가하기 위해 설계된 최첨단 벤치마킹 도구로, 실제 사용자 상호 작용을 모방하는 다양한 난이도의 작업을 통해 LLM을 평가합니다. 이 혁신적인 플랫폼은 LLM의 성능을 인간 언어와 맥락에 대한 섬세한 이해를 기반으로 평가하여 LLM의 강점과 약점에 대한 귀중한 통찰력을 제공합니다.
주요 기능
실제 작업 시뮬레이션: WildBench는 인간-GPT 상호 작용의 방대한 데이터 세트인 WildChat에서 수집한 작업을 사용하여 평가가 실제 사용자 시나리오를 반영하도록 합니다.
다양한 작업 카테고리: 12가지 카테고리의 작업을 통해 WildBench는 다양한 실제 사용자 시나리오를 포괄하며, 기존 벤치마크가 따라올 수 없는 균형 잡힌 분포를 유지합니다.
포괄적인 주석: 각 작업에는 보조 작업 유형 및 사용자 의도와 같은 자세한 주석이 포함되어 있어 응답 평가에 대한 더 깊은 수준의 통찰력을 제공합니다.
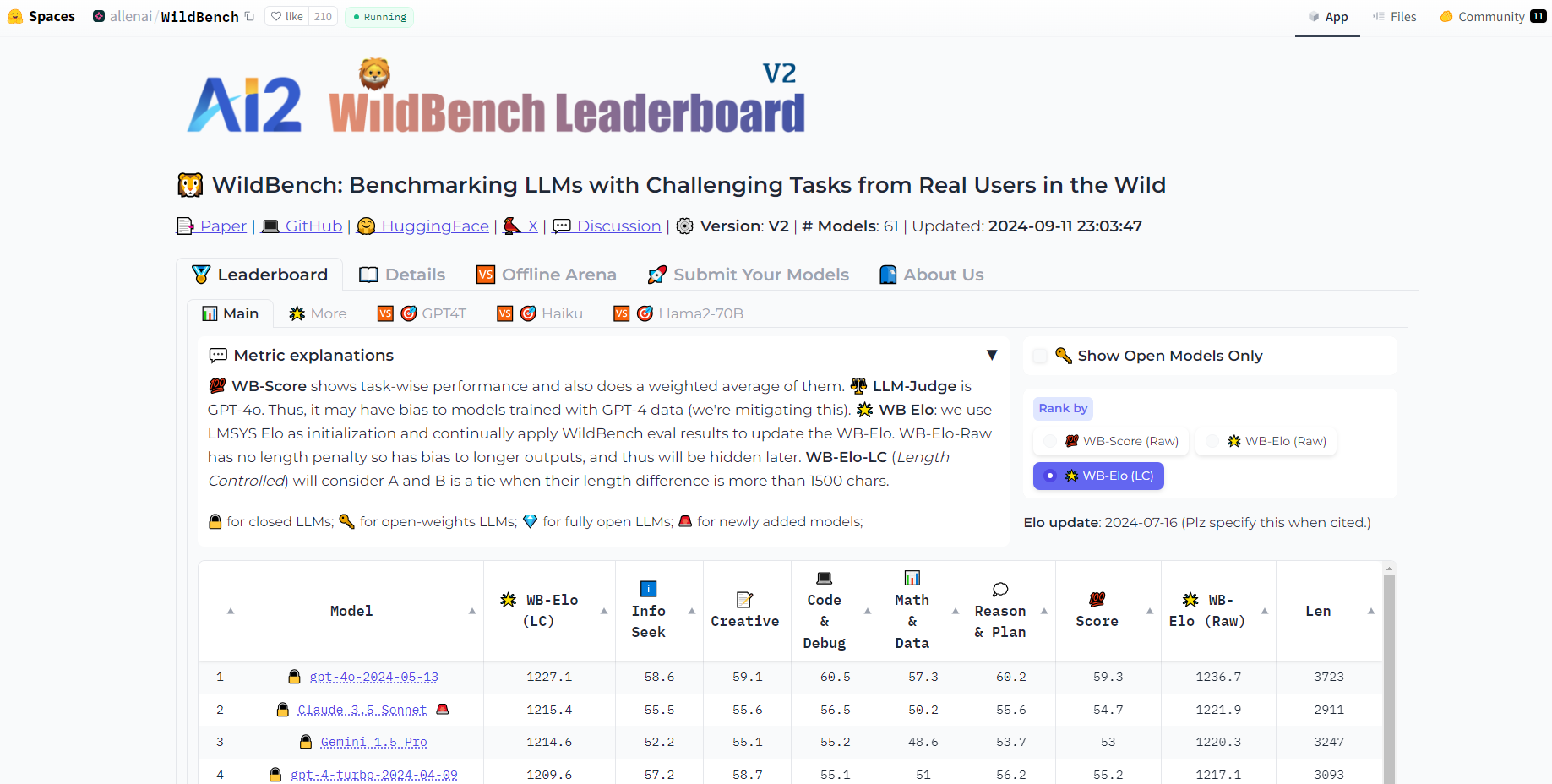
혁신적인 평가 지표: WildBench는 체크리스트 기반 채점 시스템, 개별 모델 평가를 위한 WB 점수 및 모델 간 비교 분석을 위한 WB 보상을 사용합니다.
길이 편향 완화: WildBench는 공정한 평가를 보장하기 위해 LLM 평가자가 더 긴 응답을 선호하는 경향을 상쇄하는 사용자 지정 가능한 길이 페널티 방법을 도입했습니다.
사용 사례
모델 개발자: WildBench의 포괄적인 평가를 통해 LLM의 약점을 파악하여 LLM의 성능을 향상시킵니다.
AI 연구자: 실제 작업의 복잡성에 직면했을 때 LLM의 기능에 대한 새로운 통찰력을 얻어 미래 연구 방향을 제시합니다.
기업 솔루션: 기업은 WildBench를 사용하여 고객 서비스, 콘텐츠 제작 및 기타 비즈니스 애플리케이션에 가장 적합한 LLM을 선택할 수 있습니다.
결론
WildBench는 현실적이고 섬세한 평가 플랫폼을 제공함으로써 AI 언어 모델을 평가하는 방식에 혁명을 일으키고 있습니다. WildBench의 실질적인 영향은 산업 전반에 걸쳐 확대되어 더욱 능력 있고 신뢰할 수 있는 AI 솔루션 개발을 가능하게 합니다. 실제 세계의 과제가 최첨단 AI를 만나는 WildBench로 AI의 진정한 잠재력을 발견하십시오.
More information on AI2 WildBench Leaderboard
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
AI2 WildBench Leaderboard was manually vetted by our editorial team and was first featured on 2024-09-14.
Related Searches
AI2 WildBench Leaderboard 대체품
더보기 대체품-

-

노코드 LLM 평가로 AI 제품 출시 속도를 높이세요. 180개 이상의 모델을 비교하고, 프롬프트를 만들고, 자신 있게 테스트하세요.
-

BenchLLM: LLM 응답 평가, 테스트 세트 구축, 평가 자동화. 포괄적인 성능 평가를 통해 AI 기반 시스템을 향상시킵니다.
-

-
