
What is Felafax?
Felafaxは、特にTPUなどの非NVIDIA GPUでLlama 3.1 405Bモデルのファインチューニングを大幅に低コストで最適化することで、AIトレーニングの状況を一変させます。この最先端のプラットフォームは、カスタムXLAアーキテクチャを活用して、大規模トレーニングクラスターのセットアップと管理を合理化し、NVIDIA H100のパフォーマンスを30%の費用削減で実現します。企業やスタートアップ向けに設計されたFelafaxは、複雑なマルチGPUタスクのための容易なオーケストレーションを導入し、事前に構成された環境と、さらなる効率性を求める今後のJAX実装の約束によって強化されています。
主な機能:
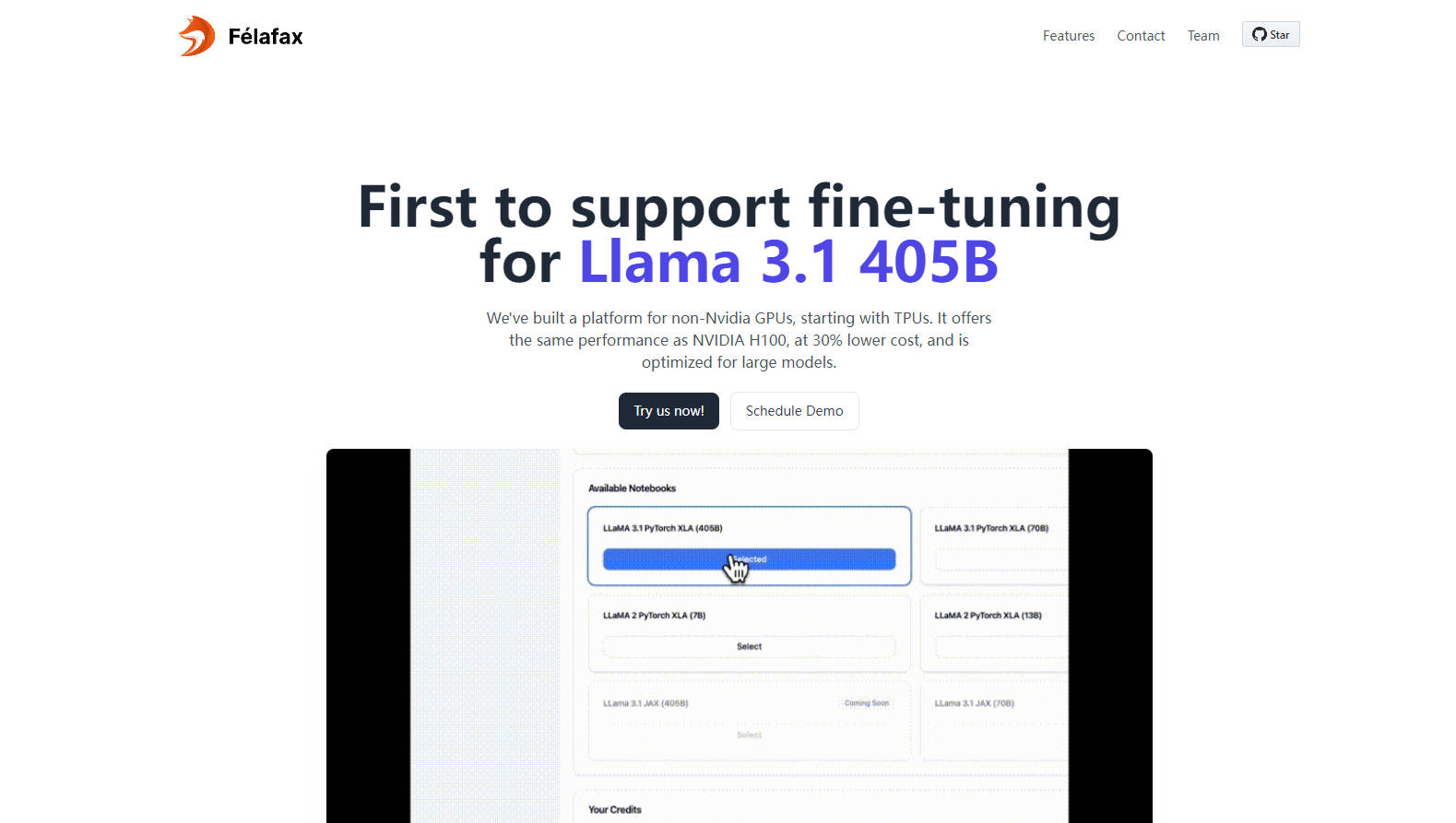
ワンクリックの大規模トレーニングクラスター- 8から1024個の非NVIDIA GPUチップから、あらゆるモデルサイズに対応するシームレスなオーケストレーションで、スケーラブルなトレーニングクラスターを即座に作成できます。
比類のないパフォーマンスとコスト効率- カスタムの非CUDA XLAフレームワークを利用することで、Felafaxは、大規模モデルに最適な、30%のコスト削減でNVIDIA H100と同等の性能を発揮します。
完全なカスタマイズと制御- テーラーメイドのトレーニングラン用の完全にカスタマイズ可能なJupyter Notebook環境にアクセスし、完全な制御と妥協のない操作を保証します。
高度なモデルパーティショニングとオーケストレーション- Llama 3.1 405B向けに最適化されたFelafaxは、モデルパーティショニング、分散チェックポイント、マルチコントローラートレーニングを管理し、比類のない容易さを実現します。
事前に構成された環境と今後のJAX統合- すべての依存関係が事前にインストールされたPytorch XLAまたはJAXを選択して、すぐに使用できます。JAX実装により、トレーニング速度が25%向上することが見込まれます。
ユースケース:
起業家による機械学習プロジェクト: AIプロジェクトに着手するスタートアップは、NVIDIAハードウェアのオーバーヘッドや費用をかけることなく、TPUで最先端の結果を実現できるようになりました。
学術機関: 大学は、高性能コンピューティングのニーズに対して費用対効果の高いソリューションを獲得し、複雑なAIモデルにおける研究と教育を強化します。
AIをスケールアップする企業: 多国籍企業は、Llama 3.1 405Bモデルのファインチューニングのニーズに対応するために、手頃な価格で高容量のインフラストラクチャを活用することで、AI開発と導入を最適化できます。
結論:
Felafaxは、非NVIDIA GPUでのコスト効率の高い高性能トレーニングを開拓し、AIコミュニティの灯台となっています。研究者、スタートアップ、あるいはスケーラブルなAIソリューションを必要とする企業のいずれであっても、Felafaxは、今日のモデルファインチューニングの未来を体験するよう招待します。200ドルのクレジットを発見し、あなた自身の条件でAIの状況を形作り始めましょう。
よくある質問:
質問: FelafaxはどのようにしてNVIDIA H100のパフォーマンスと比較して30%の低コストを実現しているのですか?
回答: Felafaxは、TPU、AWS Trainium、AMD GPU、Intel GPUなどの代替GPUでのトレーニングを最適化する、カスタムの非CUDA XLAフレームワークを利用しており、大幅に削減されたコストで同等の性能を保証します。
質問: Felafaxを今すぐ何に使用できますか?
回答: 現在、Felafaxは、AIトレーニングクラスター用のシームレスなクラウドレイヤーセットアップ、Pytorch XLAとJAX用のテーラーメイドの環境、Llama 3.1モデルの簡素化されたファインチューニングを提供しています。近日中にJAX実装が開始されるので、ご期待ください!
質問: FelafaxはLlama 405Bのような大規模モデルを処理できますか?
回答: はい、Felafaxは、Llama 3.1 405Bを含む大規模モデル向けに最適化されており、モデルパーティショニング、分散チェックポイント、トレーニングオーケストレーションを管理して、マルチGPUタスクの複雑さを軽減します。
More information on Felafax
Launched
2024-05
Pricing Model
Free Trial
Starting Price
Global Rank
9283842
Follow
Month Visit
<5k
Tech used
Cloudflare CDN,Next.js,Gzip,OpenGraph,Webpack
Top 5 Countries
100%
United States
Traffic Sources
17.32%
1.21%
0.05%
14.77%
15.42%
51.23%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 24, 2025)
Felafax was manually vetted by our editorial team and was first featured on 2024-08-02.
Felafax 代替ソフト
もっと見る 代替ソフト-

-
-

-

FriendliAIのPeriFlowで、生成AIプロジェクトを飛躍的に進化させましょう。最速のLLMサービングエンジン、柔軟な導入オプションを提供し、業界リーダーからも信頼されています。
-

LLaMA Factory は、業界で広く使用されているファインチューニング技術を統合し、Web UI インターフェースを通じてゼロコードでの大規模モデルのファインチューニングをサポートする、オープンソースのローコード大規模モデルファインチューニングフレームワークです。