
What is Felafax?
Felafax는 NVIDIA GPU가 아닌, 특히 TPU와 같은 GPU에서 Llama 3.1 405B 모델의 미세 조정을 최적화하여 AI 훈련 환경을 혁신합니다. 이를 통해 상당히 저렴한 비용으로 훈련이 가능합니다. 이 첨단 플랫폼은 맞춤형 XLA 아키텍처를 활용하여 대규모 훈련 클러스터의 설정 및 관리를 간소화하고 NVIDIA H100 성능에 필적하는 성능을 30% 저렴한 비용으로 제공합니다. 기업과 스타트업을 위해 맞춤화된 Felafax는 복잡한 다중 GPU 작업을 위한 손쉬운 오케스트레이션을 도입하며, 사전 구성된 환경과 향후 제공될 JAX 구현을 통해 더욱 향상된 효율성을 제공합니다.
주요 기능:
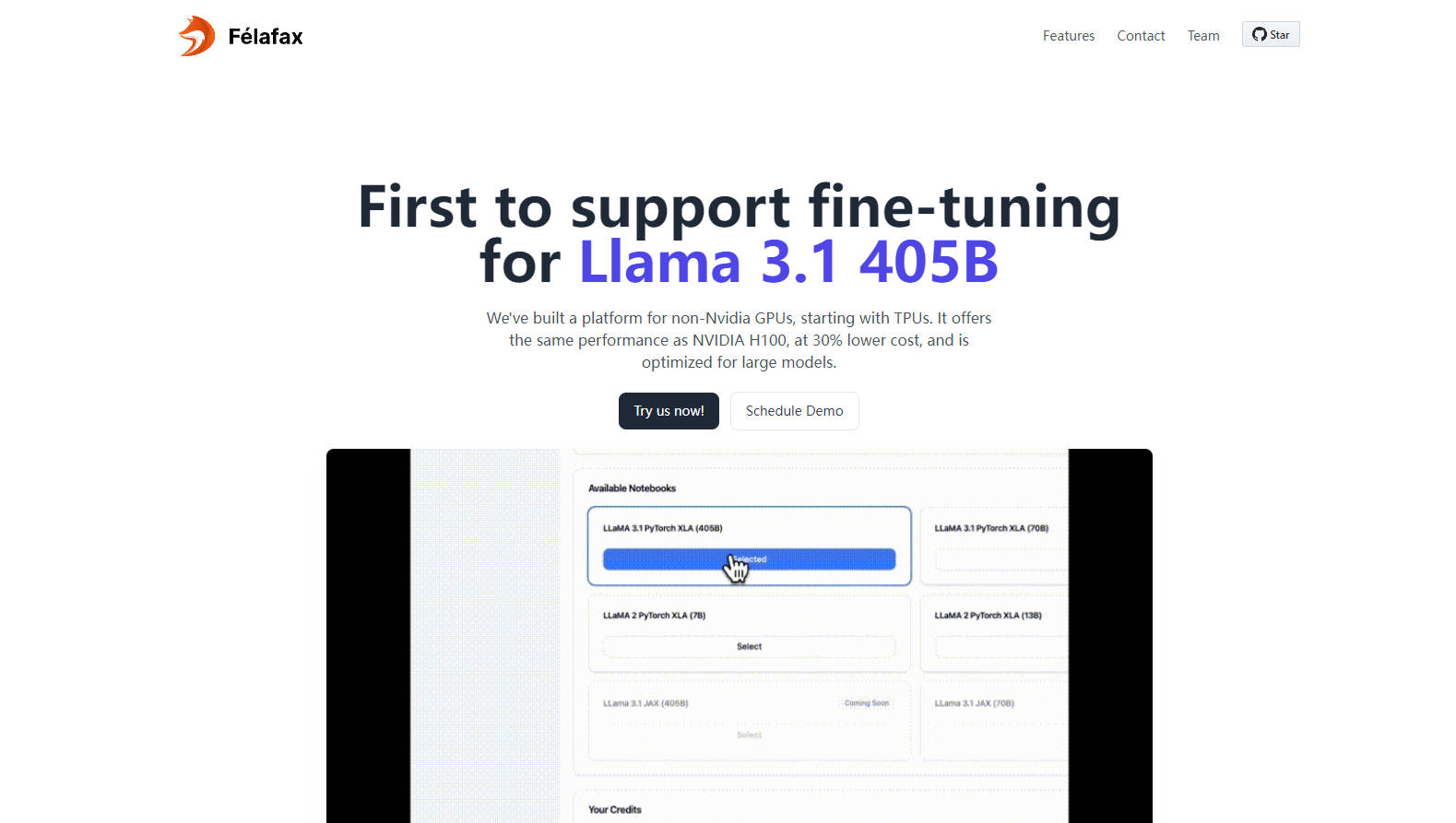
원클릭 대규모 훈련 클러스터 - 8개에서 1,024개까지의 NVIDIA GPU가 아닌 GPU 칩으로 확장 가능한 훈련 클러스터를 즉시 생성하고 모든 모델 크기에 대한 원활한 오케스트레이션을 제공합니다.
탁월한 성능 및 비용 효율성 - 맞춤형 비 CUDA XLA 프레임워크를 활용하여 Felafax는 NVIDIA H100과 동일한 성능을 30% 저렴한 비용으로 제공하여 대규모 모델에 이상적입니다.
완전한 맞춤화 및 제어 - 맞춤형 훈련 실행을 위한 완전히 사용자 지정 가능한 Jupyter Notebook 환경에 액세스하여 완벽한 제어와 0%의 타협을 보장합니다.
고급 모델 분할 및 오케스트레이션 - Llama 3.1 405B에 최적화된 Felafax는 모델 분할, 분산 체크포인트 및 다중 컨트롤러 훈련을 관리하여 탁월한 편의성을 제공합니다.
사전 구성된 환경 및 예정된 JAX 통합 - 모든 종속성이 사전 설치된 Pytorch XLA 또는 JAX 중에서 선택하여 즉시 사용할 수 있으며, JAX 구현을 통해 25% 더 빠른 훈련을 기대할 수 있습니다.
사용 사례:
기업가적 머신 러닝 프로젝트: AI 프로젝트를 시작하는 스타트업은 이제 NVIDIA 하드웨어의 오버헤드나 비용 없이 TPU에서 최첨단 결과를 얻을 수 있습니다.
학술 기관: 대학은 고성능 컴퓨팅 요구 사항에 대한 비용 효율적인 솔루션을 얻어 복잡한 AI 모델의 연구 및 교육을 강화합니다.
AI 확장 기업: 다국적 기업은 Llama 3.1 405B 모델 미세 조정 요구 사항을 위한 저렴하고 고용량 인프라를 활용하여 AI 개발 및 배포를 최적화할 수 있습니다.
결론:
Felafax는 AI 커뮤니티의 등대와 같이 NVIDIA GPU가 아닌 GPU에서 비용 효율적이고 고성능 훈련을 개척합니다. 연구자, 스타트업 또는 확장 가능한 AI 솔루션이 필요한 기업이든 Felafax는 오늘 모델 미세 조정의 미래를 경험할 수 있도록 초대합니다. $200 크레딧을 발견하고 자신만의 방식으로 AI 환경을 조성하십시오.
FAQ:
질문: Felafax는 어떻게 NVIDIA H100 성능과 비교하여 30% 저렴한 비용을 달성합니까?
답변: Felafax는 TPU, AWS Trainium, AMD GPU 및 Intel GPU와 같은 대체 GPU에서 훈련을 최적화하는 맞춤형 비 CUDA XLA 프레임워크를 활용하여 상당히 낮은 비용으로 동일한 성능을 보장합니다.
질문: 지금 Felafax를 무엇에 사용할 수 있습니까?
답변: 현재 Felafax는 AI 훈련 클러스터를 위한 원활한 클라우드 계층 설정, Pytorch XLA 및 JAX를 위한 맞춤형 환경, Llama 3.1 모델을 위한 간소화된 미세 조정을 제공합니다. 곧 출시될 JAX 구현을 기대하십시오!
질문: Felafax는 Llama 405B와 같은 대규모 모델을 처리할 수 있습니까?
답변: 네, Felafax는 Llama 3.1 405B를 포함한 대규모 모델에 최적화되어 있으며, 모델 분할, 분산 체크포인트 및 훈련 오케스트레이션을 관리하여 다중 GPU 작업의 복잡성을 완화합니다.
More information on Felafax
Launched
2024-05
Pricing Model
Free Trial
Starting Price
Global Rank
9283842
Follow
Month Visit
<5k
Tech used
Cloudflare CDN,Next.js,Gzip,OpenGraph,Webpack
Top 5 Countries
100%
United States
Traffic Sources
17.32%
1.21%
0.05%
14.77%
15.42%
51.23%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 24, 2025)
Felafax was manually vetted by our editorial team and was first featured on 2024-08-02.
Felafax 대체품
더보기 대체품-

-
-

-

FriendliAI의 PeriFlow로 생성형 AI 프로젝트에 힘을 더하세요. 최고 속도의 LLM 서빙 엔진과 유연한 배포 옵션을 제공하며, 업계 선두주자들이 신뢰하는 제품입니다.
-

LLaMA Factory는 업계에서 널리 사용되는 미세 조정 기법을 통합한 오픈 소스 저코드 대규모 모델 미세 조정 프레임워크로, 웹 UI 인터페이스를 통해 대규모 모델의 제로 코드 미세 조정을 지원합니다.