
What is Felafax?
Felafax 通过优化 Llama 3.1 405B 模型在非 NVIDIA GPU(特别是 TPU)上的微调,以显著更低的成本颠覆了 AI 训练领域。这款尖端平台简化了大规模训练集群的设置和管理,利用定制的 XLA 架构,以 30% 的成本降低实现了与 NVIDIA H100 相当的性能。Felafax 专为企业和初创公司打造,引入了轻松的复杂多 GPU 任务编排,并通过预配置环境和即将推出的 JAX 实现承诺,以实现更高的效率。
主要功能:
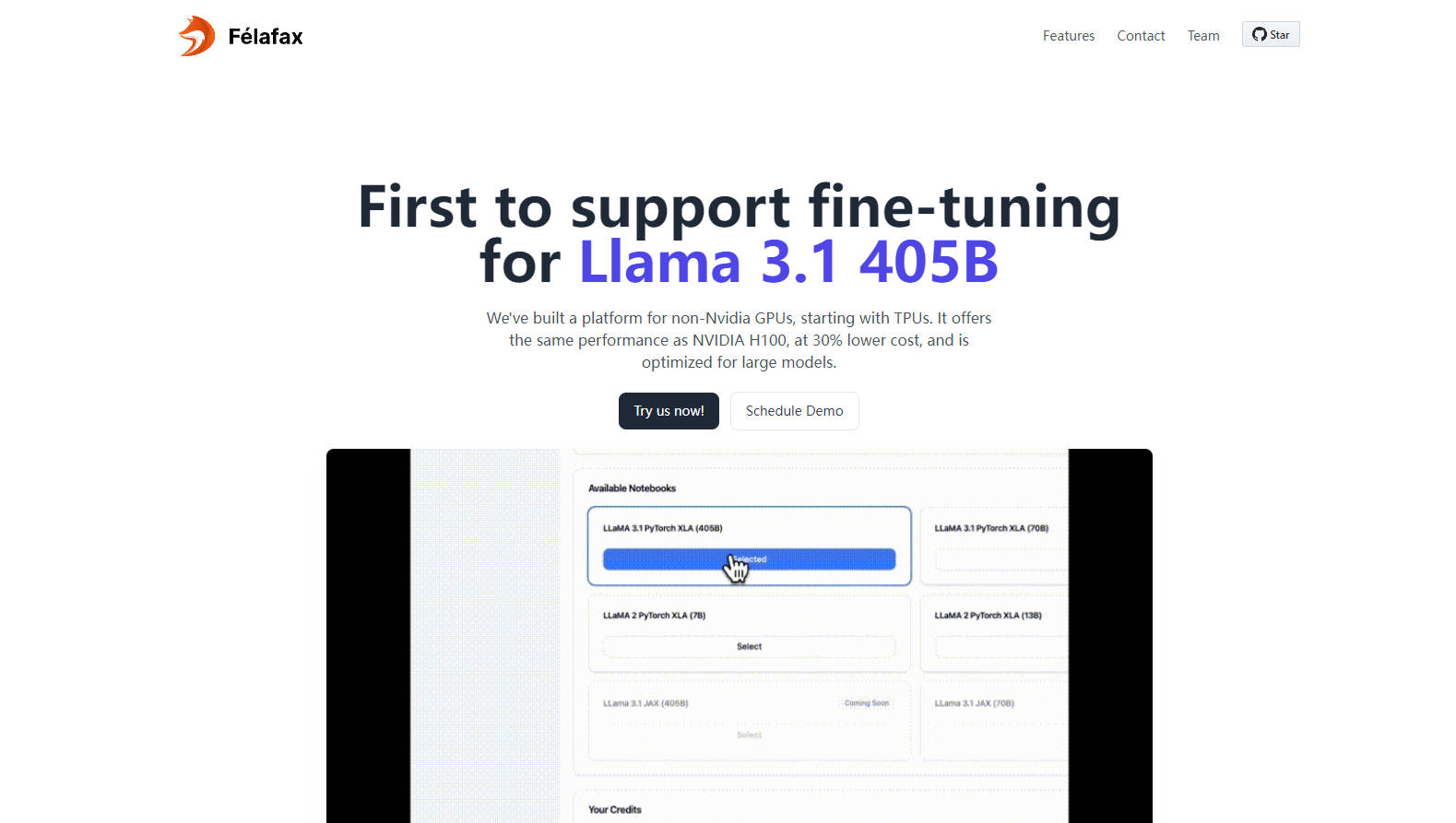
一键式大型训练集群- 立即创建可扩展的训练集群,从 8 到 1024 个非 NVIDIA GPU 芯片,并针对任何模型尺寸进行无缝编排。
无与伦比的性能和成本效益- 利用定制的非 CUDA XLA 框架,Felafax 以 30% 的成本降低提供与 NVIDIA H100 等效的性能,非常适合大型模型。
完全定制和控制- 访问完全可定制的 Jupyter 笔记本环境,以进行定制的训练运行,确保完全控制和零妥协。
高级模型分区和编排- Felafax 针对 Llama 3.1 405B 进行了优化,管理模型分区、分布式检查点和多控制器训练,以实现无与伦比的轻松体验。
预配置环境和即将推出的 JAX 集成- 在预安装所有依赖项的 Pytorch XLA 或 JAX 之间进行选择,即可立即使用,并期待 JAX 实现带来的 25% 更快的训练速度。
用例:
创业机器学习项目:现在,正在进行 AI 项目的初创公司可以在 TPU 上实现最先进的结果,而无需 NVIDIA 硬件的开销或费用。
学术机构:大学获得了经济高效的解决方案,以满足高性能计算需求,从而为复杂 AI 模型的研究和教育提供支持。
扩展 AI 的企业:跨国公司可以通过利用负担得起的高容量基础设施来满足其 Llama 3.1 405B 模型微调需求,从而优化 AI 开发和部署。
结论:
Felafax 是 AI 社区的灯塔,开创了在非 NVIDIA GPU 上进行经济高效、高性能训练的先河。无论您是研究人员、初创公司还是需要可扩展 AI 解决方案的企业,Felafax 都邀请您体验模型微调的未来。探索您的 $200 信用额度,并开始以您的方式塑造 AI 领域。
常见问题解答:
问题:Felafax 如何实现比 NVIDIA H100 性能低 30% 的成本?
答案:Felafax 利用定制的非 CUDA XLA 框架,优化了在替代 GPU(如 TPU、AWS Trainium、AMD GPU 和 Intel GPU)上的训练,确保以显著降低的成本实现同等性能。
问题:我现在可以使用 Felafax 做什么?
答案:目前,Felafax 提供了针对 AI 训练集群的无缝云层设置、针对 Pytorch XLA 和 JAX 的定制环境,以及针对 Llama 3.1 模型的简化微调。敬请关注即将推出的 JAX 实现!
问题:Felafax 可以处理像 Llama 405B 这样的大型模型吗?
答案:是的,Felafax 针对大型模型(包括 Llama 3.1 405B)进行了优化,管理模型分区、分布式检查点和训练编排,以简化多 GPU 任务的复杂性。
More information on Felafax
Launched
2024-05
Pricing Model
Free Trial
Starting Price
Global Rank
9283842
Follow
Month Visit
<5k
Tech used
Cloudflare CDN,Next.js,Gzip,OpenGraph,Webpack
Top 5 Countries
100%
United States
Traffic Sources
17.32%
1.21%
0.05%
14.77%
15.42%
51.23%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 24, 2025)
Felafax was manually vetted by our editorial team and was first featured on 2024-08-02.
Felafax 替代方案
更多 替代方案-

-
-

-

使用FriendliAI的PeriFlow,为您的生成式AI项目注入强劲动力。最快的大型语言模型(LLM)服务引擎,部署方式灵活,深受行业领导者的信赖。
-

LLaMA Factory 是一款开源的低代码大型模型微调框架,它集成了业界广泛使用的微调技术,并通过 Web UI 界面支持大型模型的零代码微调。