What is nanochat?
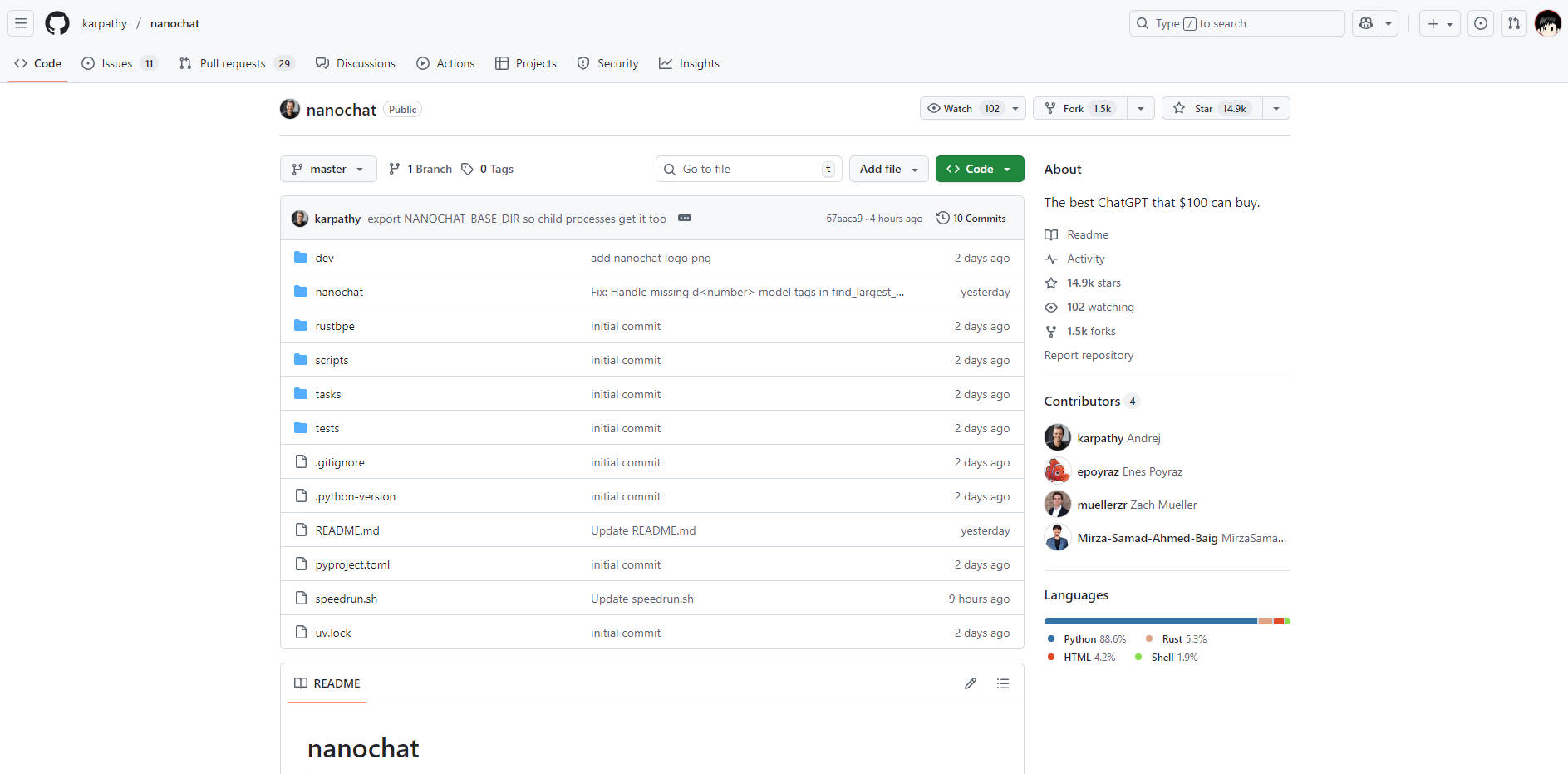
nanochat 是一個專為開發者和研究人員設計的現代大型語言模型(LLM)實作,其特色是完整、極簡且高度易於使用。它將從詞元化到功能性網路使用者介面的整個開發流程,整合到大約 1000 行乾淨、易於修改的程式碼中,成功解決了大型語言模型開發中常見的複雜性與高昂成本問題。對於任何希望透過從頭到尾建構和執行自己的模型來掌握大型語言模型技術棧的人而言,nanochat 提供了一個無與倫比的學習與原型開發環境。
主要特色
nanochat 的設計旨在讓使用者能夠全面理解和輕鬆操作,使您能夠在一個緊湊且專用的系統上,完全掌控大型語言模型生命週期的每個階段。
🛠️ 端到端流程整合
不同於那些將關鍵組件抽象化的框架,nanochat 提供了一個涵蓋詞元化、預訓練、微調、評估、推論以及簡潔網路介面的全棧實作。這種整合設計確保您僅需透過一個自動化腳本(speedrun.sh),即可執行整個流程,並獲得即時且可驗證的結果。
💡 極簡且易於修改的程式碼庫
整個實作位於一個約 1000 行、輕量級依賴(採用 Python、Rust、HTML 和 Shell)的程式碼庫中。這種極簡架構大幅降低了認知負荷,使開發者能夠閱讀、理解並修改系統的每個組件,而無需應對龐大的配置物件或複雜的工廠模式。
💰 經濟實惠的單節點部署
您可以在單一 8XH100 節點上,以不到 1000 美元的成本實現完整的大型語言模型訓練與部署。例如,$100 tier 模型約可在四小時內完成訓練與推論,使大規模的大型語言模型實驗在務實的預算範圍內也能進行。這種高效率歸功於精心的資源管理和簡潔的程式碼,成功避免了數百萬美元的巨額資本支出。
📈 可擴展的性能層級
儘管預設的 speedrun 旨在提供一個用於概念驗證的基礎模型(約 4e19 FLOPs),nanochat 的架構設計本身即具備可擴展性。開發者只需調整模型深度等少數參數,並透過裝置批次大小來管理記憶體,即可轉換至更大、能力更強的模型(例如,略優於 GPT-2 CORE 分數的 ~$300 tier)。
使用案例
nanochat 旨在將理論知識轉化為具體可執行的模型,使其成為教育與快速開發的理想工具。
1. 掌握大型語言模型技術棧
如果您是一位開發者,希望超越黑箱 API 呼叫,真正理解大型語言模型的運作機制,那麼 nanochat 將是您的最佳實驗室。透過執行完整的流程腳本,您將親身見證從原始資料到對話式網路使用者介面的整個訓練過程,從而深入且實踐性地掌握底層原理和演算法。
2. 快速原型開發與疊代
利用這個極簡程式碼庫,您可以快速測試模型架構的修改、優化技術或新穎的微調方法。由於整個技術棧都整合在一個單一節點上並易於執行,您將能大幅縮短在大型語言模型領域驗證新想法所需的典型開發週期時間。
3. 建構高度專業化的微型模型
利用 nanochat 的高效能,您可以建立客製化、更小的模型,以適應特定的領域任務或內部應用程式。能夠以經濟高效的方式執行完整的訓練和微調流程,使組織無需投入龐大、專用的機器學習基礎設施,即可開發專有的微型模型。
獨特優勢
nanochat 的價值主張在於其在完整性、可及性和成本效益之間取得的獨特平衡,為過於複雜的大型語言模型框架提供了一個明確的替代方案。
無與倫比的認知可及性: 有意地專注於極簡程式碼庫,意味著沒有複雜、錯綜的配置物件或冗餘的條件判斷結構。程式碼被設計為一個「強大基準」,易於閱讀、具內聚性,且最大程度地支援分支(fork),大幅縮短了開發者全面理解系統所需的時間。
可驗證的指標與評估: 每次執行都會生成一份詳盡的
report.md檔案,其中包含詳細的評估指標(例如:ARC-Challenge、MMLU、GSM8K 分數)。這種對可量化結果的承諾,確保您能夠科學地追蹤您所做修改和訓練執行的效能與影響。專為實踐中學習而設計: 作為 LLM101n 的畢業專題,nanochat 從根本上被設計為一個教育工具。它將現代大型語言模型開發的複雜性提煉成一個可實現、可運行的專案,確保學習曲線在知識增長上是陡峭的,而非止步於設定上的挫折。
結論
nanochat 為開發者提供了一條直接而強大的途徑,以實現對大型語言模型的真正理解和實作掌握。透過在可負擔的預算下執行整個技術棧,您將對大型語言模型創建的每個階段獲得深刻的見解。
立即探索 nanochat 的程式碼儲存庫,開始打造您預算範圍內最棒的 ChatGPT 複製版吧!
More information on nanochat
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
nanochat was manually vetted by our editorial team and was first featured on 2025-10-15.