
Best Nemotron-4 340B Alternatives in 2025
-
Ongoing research training transformer models at scale
-

Neural Magic offers high-performance inference serving for open-source LLMs. Reduce costs, enhance security, and scale with ease. Deploy on CPUs/GPUs across various environments.
-

Discover StableLM, an open-source language model by Stability AI. Generate high-performing text and code on personal devices with small and efficient models. Transparent, accessible, and supportive AI technology for developers and researchers.
-

Technology Innovation Institute has open-sourced Falcon LLM for research and commercial utilization.
-

OLMo 2 32B: Open-source LLM rivals GPT-3.5! Free code, data & weights. Research, customize, & build smarter AI.
-
Phi-3 Mini is a lightweight, state-of-the-art open model built upon datasets used for Phi-2 - synthetic data and filtered websites - with a focus on very high-quality, reasoning dense data.
-
Neutrino is a smart AI router that lets you match GPT4 performance at a fraction of the cost by dynamically routing prompts to the best-suited model, balancing speed, cost, and accuracy.
-

KTransformers, an open - source project by Tsinghua's KVCache.AI team and QuJing Tech, optimizes large - language model inference. It reduces hardware thresholds, runs 671B - parameter models on 24GB - VRAM single - GPUs, boosts inference speed (up to 286 tokens/s pre - processing, 14 tokens/s generation), and is suitable for personal, enterprise, and academic use.
-

Nebius: High-performance AI cloud. Get instant NVIDIA GPUs, managed MLOps, and cost-effective inference to accelerate your AI development & innovation.
-

ONNX Runtime: Run ML models faster, anywhere. Accelerate inference & training across platforms. PyTorch, TensorFlow & more supported!
-

NetMind: Your unified AI platform. Build, deploy & scale with diverse models, powerful GPUs & cost-efficient tools.
-

NeuralTrust: Secure, test, & monitor generative AI. Protect data, ensure compliance, & scale confidently. AI peace of mind.
-

LoRAX (LoRA eXchange) is a framework that allows users to serve thousands of fine-tuned models on a single GPU, dramatically reducing the cost of serving without compromising on throughput or latency.
-

Transformer Lab: An open - source platform for building, tuning, and running LLMs locally without coding. Download 100s of models, finetune across hardware, chat, evaluate, and more.
-
Create custom AI models with ease using Ludwig. Scale, optimize, and experiment effortlessly with declarative configuration and expert-level control.
-
GPT-NeoX-20B is a 20 billion parameter autoregressive language model trained on the Pile using the GPT-NeoX library.
-

Meta's Llama 4: Open AI with MoE. Process text, images, video. Huge context window. Build smarter, faster!
-

Privately tune and deploy open models using reinforcement learning to achieve frontier performance.
-
Nebius AI Studio Inference Service offers hosted open-source models for fast inference. No MLOps experience needed. Choose between speed and cost. Ultra-low latency. Build apps & earn credits. Test models easily. Models like MetaLlama & more.
-
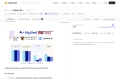
JetMoE-8B is trained with less than $ 0.1 million1 cost but outperforms LLaMA2-7B from Meta AI, who has multi-billion-dollar training resources. LLM training can be much cheaper than people generally thought.
-

Supercharge your generative AI projects with FriendliAI's PeriFlow. Fastest LLM serving engine, flexible deployment options, trusted by industry leaders.
-

Mistral Small 3 ( 2501 ) sets a new benchmark in the "small" Large Language Models category below 70B, boasting 24B parameters and achieving state-of-the-art capabilities comparable to larger models!
-
A Trailblazing Language Model Family for Advanced AI Applications. Explore efficient, open-source models with layer-wise scaling for enhanced accuracy.
-

nCompass: Streamline LLM hosting & acceleration. Cut costs, enjoy rate-limit-free API, & flexible deployment. Faster response, easy integration. Ideal for startups, enterprises & research.
-

LLaMA Factory is an open-source low-code large model fine-tuning framework that integrates the widely used fine-tuning techniques in the industry and supports zero-code fine-tuning of large models through the Web UI interface.
-
Semantic routing is the process of dynamically selecting the most suitable language model for a given input query based on the semantic content, complexity, and intent of the request. Rather than using a single model for all tasks, semantic routers analyze the input and direct it to specialized models optimized for specific domains or complexity levels.
-

OpenBMB: Building a large-scale pre-trained language model center and tools to accelerate training, tuning, and inference of big models with over 10 billion parameters. Join our open-source community and bring big models to everyone.
-
MonsterGPT: Fine-tune & deploy custom AI models via chat. Simplify complex LLM & AI tasks. Access 60+ open-source models easily.
-

TensorZero: The open-source, unified LLMOps stack. Build & optimize production-grade LLM applications with high performance & confidence.
-
OpenBioLLM-8B is an advanced open source language model designed specifically for the biomedical domain.