
Best Baichuan-7B Alternatives in 2025
-
Hunyuan-MT-7B: Open-source AI machine translation. Master 33+ languages with unrivaled contextual & cultural accuracy. WMT2025 winner, lightweight & efficient.
-

Eagle 7B : Soaring past Transformers with 1 Trillion Tokens Across 100+ Languages (RWKV-v5)
-

Baichuan-M2: Advanced medical AI for real-world clinical reasoning. Inform diagnoses, improve patient outcomes, and deploy privately on a single GPU.
-

GLM-130B: An Open Bilingual Pre-Trained Model (ICLR 2023)
-
-
ChatGLM-6B is an open CN&EN model w/ 6.2B paras (optimized for Chinese QA & dialogue for now).
-

The large language model developed by Tencent has strong Chinese creation ability.Logical reasoning in complex contexts and reliable task execution
-

Unlock the power of YaLM 100B, a GPT-like neural network that generates and processes text with 100 billion parameters. Free for developers and researchers worldwide.
-

Yuan2.0-M32 is a Mixture-of-Experts (MoE) language model with 32 experts, of which 2 are active.
-

Qwen2 is the large language model series developed by Qwen team, Alibaba Cloud.
-

Discover how TextGen revolutionizes language generation tasks with extensive model compatibility. Create content, develop chatbots, and augment datasets effortlessly.
-

XVERSE-MoE-A36B: A multilingual large language model developed by XVERSE Technology Inc.
-

BAGEL: Open-source multimodal AI from ByteDance-Seed. Understands, generates, edits images & text. Powerful, flexible, comparable to GPT-4o. Build advanced AI apps.
-
Ongoing research training transformer models at scale
-
A Gradio web UI for Large Language Models. Supports transformers, GPTQ, llama.cpp (GGUF), Llama models.
-

MiniCPM3-4B is the 3rd generation of MiniCPM series. The overall performance of MiniCPM3-4B surpasses Phi-3.5-mini-Instruct and GPT-3.5-Turbo-0125, being comparable with many recent 7B~9B models.
-

GLM-4-9B is the open-source version of the latest generation of pre-trained models in the GLM-4 series launched by Zhipu AI.
-

MiniCPM is an End-Side LLM developed by ModelBest Inc. and TsinghuaNLP, with only 2.4B parameters excluding embeddings (2.7B in total).
-

DeepSeek LLM, an advanced language model comprising 67 billion parameters. It has been trained from scratch on a vast dataset of 2 trillion tokens in both English and Chinese.
-

Discover EXAONE 3.5 by LG AI Research. A suite of bilingual (English & Korean) instruction - tuned generative models from 2.4B to 32B parameters. Support long - context up to 32K tokens, with top - notch performance in real - world scenarios.
-

WizardLM-2 8x22B is Microsoft AI's most advanced Wizard model. It demonstrates highly competitive performance compared to leading proprietary models, and it consistently outperforms all existing state-of-the-art opensource models.
-

C4AI Aya Vision 8B: Open-source multilingual vision AI for image understanding. OCR, captioning, reasoning in 23 languages.
-

OpenBMB: Building a large-scale pre-trained language model center and tools to accelerate training, tuning, and inference of big models with over 10 billion parameters. Join our open-source community and bring big models to everyone.
-

Unlock powerful AI for agentic tasks with LongCat-Flash. Open-source MoE LLM offers unmatched performance & cost-effective, ultra-fast inference.
-

Discover StableLM, an open-source language model by Stability AI. Generate high-performing text and code on personal devices with small and efficient models. Transparent, accessible, and supportive AI technology for developers and researchers.
-

Qwen2.5-Turbo by Alibaba Cloud. 1M token context window. Faster, cheaper than competitors. Ideal for research, dev & business. Summarize papers, analyze docs. Build advanced conversational AI.
-

Qwen2.5 series language models offer enhanced capabilities with larger datasets, more knowledge, better coding and math skills, and closer alignment to human preferences. Open-source and available via API.
-
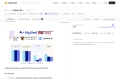
JetMoE-8B is trained with less than $ 0.1 million1 cost but outperforms LLaMA2-7B from Meta AI, who has multi-billion-dollar training resources. LLM training can be much cheaper than people generally thought.
-

Jina ColBERT v2 supports 89 languages with superior retrieval performance, user-controlled output dimensions, and 8192 token-length.
-
GPT-NeoX-20B is a 20 billion parameter autoregressive language model trained on the Pile using the GPT-NeoX library.