
2025年に最高の Baichuan-7B 代替ソフト
-
Hunyuan-MT-7B: オープンソースのAI機械翻訳。比類なき文脈と文化への深い理解に基づき、33以上の言語を高い精度で網羅します。WMT2025で優勝。軽量かつ高効率を実現。
-

-

Baichuan-M2:実臨床推論のための先進医療AI。診断を支援し、患者の転帰を改善。単一のGPU上でプライベートに展開できます。
-

-
-
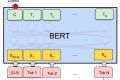
ChatGLM-6Bは、6.2Bのパラメータを持つオープンソースのCN&ENモデルです(現時点では中国語のQAと対話に最適化されています)。
-

テンセントが開発した大規模言語モデルは、中国語の創作能力に優れています。複雑なコンテキストでの論理的な推論と、信頼できるタスクの実行
-

1000億のパラメータを持つGPTのようなニューラルネットワークであるYaLM 100Bの力を解き放ちましょう。テキストの生成と処理を行います。世界中の開発者と研究者向けに無料提供。
-

Yuan2.0-M32は、32のエキスパートを持つMixture-of-Experts(MoE)言語モデルであり、そのうち2つがアクティブです。
-

-

TextGenが、広範なモデル互換性によってどのように言語生成タスクを革新するのかをご覧ください。コンテンツの作成、チャットボットの開発、およびデータセットの拡張を手間なく行います。
-

XVERSE-MoE-A36B: XVERSE Technology Inc.が開発した多言語対応の大規模言語モデル。
-

BAGEL:ByteDance-Seed発のオープンソース多モーダルAI。画像とテキストを理解、生成、編集できます。強力かつ柔軟で、GPT-4oに匹敵。高度なAIアプリケーションを構築できます。
-
-
大型言語モデルのための Gradio Web UI。transformers、GPTQ、llama.cpp(GGUF)、Llama モデルに対応。
-

MiniCPM3-4Bは、MiniCPMシリーズの第3世代です。MiniCPM3-4Bの総合的なパフォーマンスは、Phi-3.5-mini-InstructやGPT-3.5-Turbo-0125を凌駕し、最近の7B~9Bモデルの多くと匹敵するレベルです。
-

Zhipu AIが発表した最新世代の事前学習済みモデルシリーズGLM-4のオープンソースバージョンであるGLM-4-9B。
-

MiniCPM は、ModelBest Inc. と TsinghuaNLP が開発した End-Side LLM で、埋め込みを除いたパラメーターはわずか 2.4B(合計 2.7B)です。
-

DeepSeek LLMは、670億のパラメータから構成される高度な言語モデルです。英語と中国語の2兆のトークンからなる広大なデータセットでゼロからトレーニングされました。
-

LG AI ResearchのEXAONE 3.5を発見しましょう。パラメータ数が24億から320億までの、英語と韓国語のバイリンガルの命令微調整済み生成モデルのセットです。最大32Kトークンの長文コンテキストをサポートし、実世界のシナリオで一流の性能を発揮します。
-

Microsoft AIの最先端ウィザードモデル、WizardLM-2 8x22Bは、主要な独自のモデルと比較しても非常に競争力のあるパフォーマンスを発揮し、既存の最先端のオープンソースモデルを常に上回っています。
-

C4AI Aya Vision 8B:画像理解のためのオープンソース多言語ビジョンAI。OCR、キャプション生成、推論を23言語で実現。
-

OpenBMB: 100億以上のパラメーターを持つビッグモデルのトレーニング、チューニング、推論を迅速化するための、大規模な事前トレーニング済言語モデルセンターとツールを構築します。私たちのオープンソースコミュニティに参加して、ビッグモデルをすべての人に提供しましょう。
-

LongCat-Flashが、エージェントタスク向けに強力なAIの力を解き放ちます。オープンソースのMoE LLMは、圧倒的なパフォーマンスと、費用対効果に優れた超高速推論を実現します。
-

Stability AIによるオープンソース言語モデル、StableLMをご紹介します。小型で効率的なモデルにより、個人デバイスで高性能なテキストとコードを生成できます。開発者と研究者向けの、透明性が高く、アクセスしやすく、サポート体制も充実したAI技術です。
-

アリババクラウドのQwen2.5-Turbo。100万トークンのコンテキストウィンドウ。競合他社よりも高速で低価格。研究、開発、ビジネスに最適です。論文の要約、文書の分析、高度な会話型AIの構築に。
-

Qwen2.5 シリーズの言語モデルは、より大規模なデータセット、豊富な知識、優れたコーディングと数学スキル、そして人間の好みへのより近い整合性を備え、強化された機能を提供します。オープンソースであり、API経由で利用可能です。
-
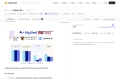
JetMoE-8Bは100万ドル未満で訓練されましたが、数10億ドルの訓練リソースを持つMeta AIのLLaMA2-7Bを上回っています。LLMの訓練は一般的に考えられているよりもずっと安価です。
-

Jina ColBERT v2は、89言語に対応し、優れた検索性能、ユーザーが制御可能な出力次元、8192トークン長のサポートを提供します。
-
GPT-NeoX-20Bは、GPT-NeoXライブラリを使用してPile上でトレーニングされた、200億パラメータの自己回帰言語モデルです。