
Best Yuan2.0-M32 Alternatives in 2025
-

XVERSE-MoE-A36B: A multilingual large language model developed by XVERSE Technology Inc.
-
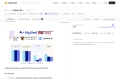
JetMoE-8B is trained with less than $ 0.1 million1 cost but outperforms LLaMA2-7B from Meta AI, who has multi-billion-dollar training resources. LLM training can be much cheaper than people generally thought.
-

MiniCPM is an End-Side LLM developed by ModelBest Inc. and TsinghuaNLP, with only 2.4B parameters excluding embeddings (2.7B in total).
-

Qwen2.5 series language models offer enhanced capabilities with larger datasets, more knowledge, better coding and math skills, and closer alignment to human preferences. Open-source and available via API.
-

DeepSeek-V2: 236 billion MoE model. Leading performance. Ultra-affordable. Unparalleled experience. Chat and API upgraded to the latest model.
-
Hunyuan-MT-7B: Open-source AI machine translation. Master 33+ languages with unrivaled contextual & cultural accuracy. WMT2025 winner, lightweight & efficient.
-

OLMo 2 32B: Open-source LLM rivals GPT-3.5! Free code, data & weights. Research, customize, & build smarter AI.
-

Gemma 3 270M: Compact, hyper-efficient AI for specialized tasks. Fine-tune for precise instruction following & low-cost, on-device deployment.
-

Unlock the power of YaLM 100B, a GPT-like neural network that generates and processes text with 100 billion parameters. Free for developers and researchers worldwide.
-

Unlock powerful AI for agentic tasks with LongCat-Flash. Open-source MoE LLM offers unmatched performance & cost-effective, ultra-fast inference.
-

Qwen2 is the large language model series developed by Qwen team, Alibaba Cloud.
-

Qwen2-Math is a series of language models specifically built based on Qwen2 LLM for solving mathematical problems.
-

Explore InternLM2, an AI tool with open-sourced models! Excel in long-context tasks, reasoning, math, code interpretation, and creative writing. Discover its versatile applications and strong tool utilization capabilities for research, application development, and chat interactions. Upgrade your AI landscape with InternLM2.
-
Semantic routing is the process of dynamically selecting the most suitable language model for a given input query based on the semantic content, complexity, and intent of the request. Rather than using a single model for all tasks, semantic routers analyze the input and direct it to specialized models optimized for specific domains or complexity levels.
-

The large language model developed by Tencent has strong Chinese creation ability.Logical reasoning in complex contexts and reliable task execution
-

MiniMax-M1: Open-weight AI model with 1M token context & deep reasoning. Process massive data efficiently for advanced AI applications.
-

WizardLM-2 8x22B is Microsoft AI's most advanced Wizard model. It demonstrates highly competitive performance compared to leading proprietary models, and it consistently outperforms all existing state-of-the-art opensource models.
-

DeepSeek LLM, an advanced language model comprising 67 billion parameters. It has been trained from scratch on a vast dataset of 2 trillion tokens in both English and Chinese.
-

The TinyLlama project is an open endeavor to pretrain a 1.1B Llama model on 3 trillion tokens.
-

Phi-2 is an ideal model for researchers to explore different areas such as mechanistic interpretability, safety improvements, and fine-tuning experiments.
-

MiniCPM3-4B is the 3rd generation of MiniCPM series. The overall performance of MiniCPM3-4B surpasses Phi-3.5-mini-Instruct and GPT-3.5-Turbo-0125, being comparable with many recent 7B~9B models.
-

To speed up LLMs' inference and enhance LLM's perceive of key information, compress the prompt and KV-Cache, which achieves up to 20x compression with minimal performance loss.
-

Baichuan-M2: Advanced medical AI for real-world clinical reasoning. Inform diagnoses, improve patient outcomes, and deploy privately on a single GPU.
-

Optimize AI Costs with Mintii! Achieve 63% savings while maintaining quality using our intelligent router for dynamic model selection.
-
With a total of 8B parameters, the model surpasses proprietary models such as GPT-4V-1106, Gemini Pro, Qwen-VL-Max and Claude 3 in overall performance.
-
Enhance your NLP capabilities with Baichuan-7B - a groundbreaking model that excels in language processing and text generation. Discover its bilingual capabilities, versatile applications, and impressive performance. Shape the future of human-computer communication with Baichuan-7B.
-

Yi Visual Language (Yi-VL) model is the open-source, multimodal version of the Yi Large Language Model (LLM) series, enabling content comprehension, recognition, and multi-round conversations about images.
-
Ship AI features faster with MegaLLM's unified gateway. Access Claude, GPT-5, Gemini, Llama, and 70+ models through a single API. Built-in analytics, smart fallbacks, and usage tracking included.
-

GLM-130B: An Open Bilingual Pre-Trained Model (ICLR 2023)
-

Build AI models from scratch! MiniMind offers fast, affordable LLM training on a single GPU. Learn PyTorch & create your own AI.