
2026年に最高の Yuan2.0-M32 代替ソフト
-

XVERSE-MoE-A36B: XVERSE Technology Inc.が開発した多言語対応の大規模言語モデル。
-
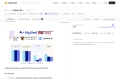
JetMoE-8Bは100万ドル未満で訓練されましたが、数10億ドルの訓練リソースを持つMeta AIのLLaMA2-7Bを上回っています。LLMの訓練は一般的に考えられているよりもずっと安価です。
-

MiniCPM は、ModelBest Inc. と TsinghuaNLP が開発した End-Side LLM で、埋め込みを除いたパラメーターはわずか 2.4B(合計 2.7B)です。
-

Qwen2.5 シリーズの言語モデルは、より大規模なデータセット、豊富な知識、優れたコーディングと数学スキル、そして人間の好みへのより近い整合性を備え、強化された機能を提供します。オープンソースであり、API経由で利用可能です。
-

DeepSeek-V2: 2360億MoEモデル。業界をリードするパフォーマンス。非常に低価格。他に類を見ない体験。チャットとAPIは最新モデルにアップグレードされています。
-
Hunyuan-MT-7B: オープンソースのAI機械翻訳。比類なき文脈と文化への深い理解に基づき、33以上の言語を高い精度で網羅します。WMT2025で優勝。軽量かつ高効率を実現。
-

OLMo 2 32B:GPT-3.5に匹敵するオープンソースLLM!コード、データ、重みを無償で提供。研究、カスタマイズ、そしてよりスマートなAIの構築に。
-

Gemma 3 270M: 特定のタスクに特化した、コンパクトかつ超高効率なAI。正確な指示追従と低コストなオンデバイス展開向けにファインチューニング可能。
-

1000億のパラメータを持つGPTのようなニューラルネットワークであるYaLM 100Bの力を解き放ちましょう。テキストの生成と処理を行います。世界中の開発者と研究者向けに無料提供。
-

LongCat-Flashが、エージェントタスク向けに強力なAIの力を解き放ちます。オープンソースのMoE LLMは、圧倒的なパフォーマンスと、費用対効果に優れた超高速推論を実現します。
-

-

-

InternLM2 を探索しましょう。オープンソースのモデルを搭載した AI ツールです。長文コンテキストでの作業、推論、数学、コード解釈、創作などに優れています。研究、アプリケーション開発、チャットでのやり取りに、その多様なアプリケーションと強力なツールとしての活用能力を発見しましょう。InternLM2 で AI のランドスケープをアップグレードしましょう。
-
セマンティックルーティングとは、入力されたクエリに対し、そのセマンティックな内容、複雑性、および意図を基に、最適な言語モデルを動的に選択する仕組みです。全てのタスクに単一のモデルを用いるのではなく、セマンティックルーターは入力を分析し、特定のドメインや複雑度レベルに合わせて最適化された専用モデルへと振り分けます。
-

テンセントが開発した大規模言語モデルは、中国語の創作能力に優れています。複雑なコンテキストでの論理的な推論と、信頼できるタスクの実行
-

MiniMax-M1: 100万トークンのコンテキストと高度な推論能力を備えた重み公開型AIモデル。高度なAIアプリケーション向けに、膨大なデータを効率的に処理します。
-

Microsoft AIの最先端ウィザードモデル、WizardLM-2 8x22Bは、主要な独自のモデルと比較しても非常に競争力のあるパフォーマンスを発揮し、既存の最先端のオープンソースモデルを常に上回っています。
-

DeepSeek LLMは、670億のパラメータから構成される高度な言語モデルです。英語と中国語の2兆のトークンからなる広大なデータセットでゼロからトレーニングされました。
-

TinyLlama プロジェクトは、11億のパラメータを持つ Llama モデルを3兆トークンで事前学習させるためのオープンな取り組みです。
-

Phi-2 は、機械的解釈可能性、安全性向上、微調整実験などのさまざまな分野を探究する研究者にとって理想的なモデルです。
-

MiniCPM3-4Bは、MiniCPMシリーズの第3世代です。MiniCPM3-4Bの総合的なパフォーマンスは、Phi-3.5-mini-InstructやGPT-3.5-Turbo-0125を凌駕し、最近の7B~9Bモデルの多くと匹敵するレベルです。
-

LLMの推論を高速化し、LLMが重要な情報を認識できるように、プロンプトとKVキャッシュを圧縮します。これにより、パフォーマンスをほとんど低下させることなく、最大20倍の圧縮を実現します。
-

Baichuan-M2:実臨床推論のための先進医療AI。診断を支援し、患者の転帰を改善。単一のGPU上でプライベートに展開できます。
-

MintiiでAIコストを最適化!動的なモデル選択を可能にするインテリジェントルーターを活用し、品質を維持しながら63%のコスト削減を実現します。
-
80億のパラメータを持つこのモデルは、GPT-4V-1106、Gemini Pro、Qwen-VL-Max、Claude 3などの独自モデルを総合的なパフォーマンスで上回ります。
-
Baichuan-7BでNLP機能を強化しましょう。これは、言語処理とテキスト生成に優れた画期的なモデルです。バイリンガルの機能、多様なアプリケーション、優れたパフォーマンスを発見してください。Baichuan-7Bで人間とコンピュータのコミュニケーションの未来を形作ります。
-

Yi Visual Language(Yi-VL)モデルは、Yi Large Language Model(LLM)シリーズのオープンソースであり、マルチモーダルバージョンで、コンテンツの理解、認識、および画像に関する複数ラウンドの会話を実現します。
-
MegaLLMの統合ゲートウェイで、AI機能をより迅速にリリース。単一のAPIを通じて、Claude、GPT-5、Gemini、Llamaなど70以上のモデルにアクセス可能。組み込みの分析機能、スマートフォールバック、利用状況のトラッキングも標準搭載。
-

-

AIモデルをゼロから構築しよう! MiniMind なら、手頃な価格で、シングルGPU上で高速なLLMトレーニングが可能です。PyTorchを学んで、あなただけのAIを作り上げましょう。