
2025 Лучших AI2 WildBench Leaderboard Альтернативи
-

LiveBench – это бенчмарк для больших языковых моделей (LLM) с ежемесячными новыми вопросами из различных источников и объективными ответами для точного оценивания. В настоящее время представлено 18 задач в 6 категориях, и в будущем их станет еще больше.
-

Запускайте продукты на основе ИИ быстрее с помощью бескликовой оценки больших языковых моделей. Сравнивайте более 180 моделей, создавайте запросы и тестируйте с уверенностью.
-

BenchLLM: Оценивайте ответы больших языковых моделей, создавайте наборы тестов, автоматизируйте оценку. Повышайте качество систем на основе ИИ с помощью всесторонней оценки производительности.
-

Web Bench представляет собой новый, открытый и всеобъемлющий набор данных для бенчмаркинга, специально разработанный для оценки производительности веб-агентов на основе ИИ в решении сложных, реальных задач на широком спектре действующих веб-сайтов.
-

xbench: Бенчмарк ИИ, оценивающий реальную полезность и передовые возможности. Получите точную, динамичную оценку ИИ-агентов с помощью нашей двухканальной системы.
-

Изучите таблицу лидеров вызова функций Беркли (также известную как таблица лидеров вызова инструментов Беркли), чтобы увидеть, насколько хорошо большие языковые модели могут вызывать функции (также называемые инструментами) с точностью.
-

Выбирайте лучшего AI-агента, отвечающего вашим потребностям, с помощью Agent Leaderboard — объективного анализа производительности в реальных условиях, основанного на 14 критериях оценки.
-

Deepchecks: Комплексная платформа для оценки LLM. Систематически тестируйте, сравнивайте и отслеживайте ваши ИИ-приложения от разработки до продакшена. Минимизируйте галлюцинации и ускорьте внедрение.
-

BenchX: Инструмент для бенчмаркинга и улучшения AI-агентов. Отслеживайте решения, логи и метрики. Интегрируйте в CI/CD. Получайте практически применимые инсайты.
-

ZeroBench: оптимальный бенчмарк для мультимодальных моделей, проверяющий визуальное мышление, точность и вычислительные навыки с помощью 100 сложных вопросов и 334 подвопросов.
-
Weights & Biases: Единая ИИ-платформа для разработчиков, предназначенная для ускоренного создания, оценки и управления ML-моделями, LLM и агентами.
-

Данная таблица лидеров для оценки поставщиков LLM работает на основе данных Klu.ai в режиме реального времени, что позволяет выбрать оптимальный API и модель для ваших нужд.
-
Изучите различные модели генерации текста, составляя сообщения и настраивая свои ответы.
-

Braintrust: Комплексная платформа для разработки, тестирования и мониторинга надежных ИИ-приложений. Получайте предсказуемые, высококачественные результаты LLM.
-
Легко оценивайте большие языковые модели с помощью PromptBench. Оценивайте производительность, улучшайте возможности модели и проверяйте устойчивость к вредоносным запросам.
-

Компании всех размеров используют Confident AI, чтобы обосновать, почему их LLM заслуживают места в процессе производства.
-

Geekbench AI - это кроссплатформенный бенчмарк для ИИ, который использует реальные задачи машинного обучения для оценки производительности рабочих нагрузок ИИ.
-

Ваш главный ресурс для сравнения моделей ИИ по всему миру. Откройте для себя, оцените и проведите сравнительный анализ последних достижений в области искусственного интеллекта в различных сферах применения.
-

Рейтинг открытых языковых моделей Huggingface направлен на поощрение открытого сотрудничества и прозрачности в оценке языковых моделей.
-

Рейтинг SEAL демонстрирует, что семейство больших языковых моделей (LLM) GPT от OpenAI занимает первое место в трех из четырех начальных областей, которые они используют для ранжирования моделей ИИ, а популярный Claude 3 Opus от Anthropic PBC занимает первое место в четвертой категории. Модели Gemini от Google LLC также показали хорошие результаты, разделив первое место с моделями GPT в паре областей.
-

WizardLM-2 8x22B — самая продвинутая модель Wizard от Microsoft AI. Она демонстрирует высокую конкурентоспособность по сравнению с ведущими коммерческими моделями и превосходит все существующие передовые модели с открытым исходным кодом.
-

LLMWizard — это единая платформа на основе искусственного интеллекта, предоставляющая доступ к нескольким передовым моделям ИИ по одной подписке. Она предлагает такие функции, как создание пользовательских помощников ИИ, анализ PDF-файлов, разработка чат-ботов/помощников и инструменты для командной работы.
-

Сравнивайте результаты работы ChatGPT, Claude и Gemini мгновенно, используя один и тот же запрос. Наша платформа идеально подходит для исследователей, создателей контента и энтузиастов ИИ, помогая вам выбрать лучшую языковую модель для ваших задач, гарантируя оптимальные результаты и эффективность.
-

Изучите InternLM2, ИИ-инструмент с открытыми моделями! Достигайте высоких результатов в задачах с большим контекстом, рассуждениях, математике, интерпретации кода и творческом письме. Откройте для себя его универсальные приложения и мощные возможности использования инструментов для исследований, разработки приложений и взаимодействия в чате. Обновите свой ИИ-ландшафт с помощью InternLM2.
-
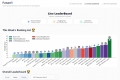
FutureX: Динамически оценивайте прогностические способности LLM-агентов в реальных условиях для предсказания будущих событий. Получите незамутненные инсайты об истинном интеллекте ИИ.
-
Stax: Развертывайте LLM-приложения с уверенностью. Оценивайте модели ИИ и промты, опираясь на ваши уникальные критерии, для получения глубоких выводов, основанных на данных. Развивайте ИИ лучше и быстрее.
-
Платформа LangWatch на базе открытого кода обеспечивает простое итерационное улучшение текущих конвейеров LLM, а также снижает риски, такие как побег из изоляции, утечка конфиденциальных данных и галлюцинации.
-

LightEval — это легкий набор инструментов для оценки больших языковых моделей (LLM), который Hugging Face использует внутри компании с недавно выпущенными библиотеками для обработки данных LLM datatrove и для обучения LLM nanotron.
-

Alpha Arena: Эталон оценки инвестиций в ИИ в реальных условиях. Тестируйте модели ИИ, используя реальный капитал на действующих финансовых рынках, чтобы доказать их эффективность и управлять рисками.
-

Windows Agent Arena (WAA) - это открытая тестовая среда для агентов ИИ в Windows. Предоставляет агентам возможность выполнять разнообразные задачи, сокращая время оценки. Идеально подходит для исследователей и разработчиков в области искусственного интеллекта.