
Best ZeroBench Alternatives in 2026
-

xbench: The AI benchmark tracking real-world utility and frontier capabilities. Get accurate, dynamic evaluation of AI agents with our dual-track system.
-

LiveBench is an LLM benchmark with monthly new questions from diverse sources and objective answers for accurate scoring, currently featuring 18 tasks in 6 categories and more to come.
-

WildBench is an advanced benchmarking tool that evaluates LLMs on a diverse set of real-world tasks. It's essential for those looking to enhance AI performance and understand model limitations in practical scenarios.
-

BenchX: Benchmark & improve AI agents. Track decisions, logs, & metrics. Integrate into CI/CD. Get actionable insights.
-

Web Bench is a new, open, and comprehensive benchmark dataset specifically designed to evaluate the performance of AI web browsing agents on complex, real-world tasks across a wide variety of live websites.
-

Launch AI products faster with no-code LLM evaluations. Compare 180+ models, craft prompts, and test confidently.
-
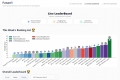
FutureX: Dynamically evaluate LLM agents' real-world predictive power for future events. Get uncontaminated insights into true AI intelligence.
-
Evaluate Large Language Models easily with PromptBench. Assess performance, enhance model capabilities, and test robustness against adversarial prompts.
-

TensorZero: The open-source, unified LLMOps stack. Build & optimize production-grade LLM applications with high performance & confidence.
-
A refinery for your data and models, FiftyOne from Voxel51 enables you to build production-ready visual AI applications easily, efficiently, and at scale.
-

BenchLLM: Evaluate LLM responses, build test suites, automate evaluations. Enhance AI-driven systems with comprehensive performance assessments.
-

Braintrust: The end-to-end platform to develop, test & monitor reliable AI applications. Get predictable, high-quality LLM results.
-

Zenbase simplifies AI dev. It automates prompt eng. & model opt., offers reliable tool calls, continuous opt., & enterprise-grade security. Save time, scale smarter. Ideal for devs!
-

Repo for the Belebele dataset, a massively multilingual reading comprehension dataset.
-
Design Arena: The definitive, community-driven benchmark for AI design. Objectively rank models & evaluate their true design quality and taste.
-

Geekbench AI is a cross-platform AI benchmark that uses real-world machine learning tasks to evaluate AI workload performance.
-

Measure language model truthfulness with TruthfulQA, a benchmark of 817 questions across 38 categories. Avoid false answers based on misconceptions.
-

Explore DeepSeek-R1, a cutting-edge reasoning model powered by RL, outperforming benchmarks in math, code, and reasoning tasks. Open-source and AI-driven.
-

Cambrian-1 is a family of multimodal LLMs with a vision-centric design.
-

Alpha Arena: The real-world benchmark for AI investment. Test AI models with actual capital in live financial markets to prove performance & manage risk.
-

Baichuan-M2: Advanced medical AI for real-world clinical reasoning. Inform diagnoses, improve patient outcomes, and deploy privately on a single GPU.
-

Confucius-o1-14B, a NetEase Youdao-developed o1 - like reasoning model. Deployable on single GPU. Based on Qwen2.5-14B-Instruct, it has unique summarizing ability. Explore how it simplifies problem - solving on our product page!
-

DeepCoder: 64K context code AI. Open-source 14B model beats expectations! Long context, RL training, top performance.
-

MMStar, a benchmark test set for evaluating large-scale multimodal capabilities of visual language models. Discover potential issues in your model's performance and evaluate its multimodal abilities across multiple tasks with MMStar. Try it now!
-
Free, unbiased testing for OCR & VLM models. Evaluate document parsing AI with your own files, get real-world performance insights & rankings.
-

Boost search accuracy with Qwen3 Reranker. Precisely rank text & find relevant info faster across 100+ languages. Enhance Q&A & text analysis.
-

Choose the best AI agent for your needs with the Agent Leaderboard—unbiased, real-world performance insights across 14 benchmarks.
-

VERO: The enterprise AI evaluation framework for LLM pipelines. Quickly detect & fix issues, turning weeks of QA into minutes of confidence.
-
Jan-v1: Your local AI agent for automated research. Build private, powerful apps that generate professional reports & integrate web search, all on your machine.
-
ZenMux simplifies enterprise LLM orchestration. Unified API, intelligent routing, and pioneering AI model insurance ensure guaranteed quality & reliability.