
2025年最好的 ZeroBench 替代方案
-

-

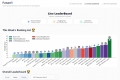
LiveBench 是一個大型語言模型基準測試,每月從不同來源獲得新問題和客觀答案,以進行準確評分。目前包含 6 個類別的 18 個任務,並將陸續增加更多任務。
-

WildBench 是一個先進的基準測試工具,用於評估 LLM 在各種真實世界任務中的表現。對於那些希望提升 AI 效能並了解模型在實際情境中的局限性的人來說,它是必不可少的工具。
-

-

Web Bench 是一個嶄新、開放且全面的基準測試資料集,專門設計來評估 AI 網頁瀏覽代理在處理複雜的真實世界任務時,於各式各樣的實際運作網站上的效能表現。
-

-
-
-

TensorZero:一套開源且統一的 LLMOps 技術堆疊。助您輕鬆打造與優化生產級的 LLM 應用程式,確保高效能與高可靠性。
-
Voxel51 的 FiftyOne,一個專為您的數據和模型打造的精煉廠,讓您能輕鬆、高效且大規模地建構可投入生產的視覺 AI 應用程式。
-

BenchLLM:評估大型語言模型 (LLM) 回應,建立測試套件,自動化評估流程。透過全面的效能評估,提升 AI 系統效能。
-

-

Zenbase 簡化 AI 開發流程。它自動化提示工程和模型優化,提供可靠的工具調用、持續優化和企業級安全性。節省時間,更聰明地擴展規模。非常適合開發人員!
-

-
-

Geekbench AI 是一個跨平台的 AI 基準測試工具,它使用真實世界的機器學習任務來評估 AI 工作負載效能。
-

使用 TruthfulQA 來衡量語言模型真實性,TruthfulQA 是一個橫跨 38 個類別、包含 817 個問題的基準。避免基於錯誤觀念而提出的錯誤答案。
-

探索 DeepSeek-R1,一款由強化學習 (RL) 技術驅動的尖端推理模型,其在數學、程式碼和推理任務上的表現超越了基準測試。開源且由 AI 驅動。
-

-

-

Baichuan-M2:專為真實世界臨床推論設計的先進醫療人工智慧。協助診斷、提升病患預後,並可於單一GPU上進行私有化部署。
-

Confucius-o1-14B,是由网易有道開發的類o1推理模型。可在單顆GPU上部署。基於Qwen2.5-14B-Instruct,它擁有獨特的摘要能力。快來我們的產品頁面探索它如何簡化問題解決!
-

DeepCoder:具備 64K 上下文長度的程式碼 AI。開源 14B 模型表現超乎預期!具備長上下文、RL 訓練,效能頂尖。
-

MMStar,一個評估視覺語言模型大規模多模態功能的基準測試集。利用 MMStar 找出模型效能的潛在問題,並在多項任務中評估其多模態能力。立即試用!
-
Free, unbiased testing for OCR & VLM models. Evaluate document parsing AI with your own files, get real-world performance insights & rankings.
-

運用 Qwen3 Reranker 提升搜尋精準度。能精準地為文本排序,並於逾百種語言中,更快找到相關資訊。強化問答與文本分析能力。
-

透過 Agent Leaderboard 選擇最符合您需求的 AI 代理程式——此排行榜提供橫跨 14 項基準的公正、真實效能見解。
-

-
-
ZenMux 簡化企業級大型語言模型 (LLM) 的編排工作。其提供統一的 API 介面、智慧路由,並首創人工智慧模型保險,全面確保品質與可靠性。