2025年最好的 ZeroBench 替代方案
-

-

LiveBench 是一款 LLM 基准测试,每月从不同来源收集新的问题,并提供客观答案以进行准确评分。目前涵盖 6 个类别中的 18 个任务,并将不断增加更多任务。
-

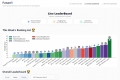
WildBench 是一款先进的基准测试工具,用于评估大型语言模型 (LLM) 在各种现实世界任务中的表现。对于那些希望提高 AI 性能并了解模型在实际场景中的局限性的用户来说,它至关重要。
-

BenchX:用于评估和提升 AI 智能体的性能。跟踪决策过程、日志和各项指标,并可集成到 CI/CD 流程中,助您获得可执行的洞察分析。
-

Web Bench 是一个全新、开放、全面的基准数据集,旨在专门评估 AI 网络浏览智能体在涵盖广泛多样的实时网站的复杂真实世界任务上的性能。
-

无需编码即可快速推出 AI 产品,并对大型语言模型 (LLM) 进行评估。比较 180 多个模型,精心设计提示词,并充满信心地进行测试。
-
-
-

TensorZero:一个开源、统一的 LLMOps 技术栈。助您高效构建并优化生产级 LLM 应用,确保高性能与高可靠性。
-
-

-

-

Zenbase 简化 AI 开发流程。它自动化提示工程和模型优化,提供可靠的工具调用、持续优化和企业级安全保障。节省时间,更智能地扩展规模。非常适合开发者!
-

-
-

Geekbench AI 是一款跨平台 AI 基准测试工具,它使用现实世界的机器学习任务来评估 AI 工作负载性能。
-

-

探索DeepSeek-R1,一款由强化学习 (RL) 驱动、尖端推理模型,在数学、代码和推理任务中超越基准测试。开源且由AI驱动。
-

-

Alpha Arena:AI投资的实战标杆。将AI模型置于真实的金融市场中,投入真金白银进行测试,从而验证其性能,并有效管控风险。
-

-

Confucius-o1-14B,网易有道研发的类o1推理模型。可在单GPU上部署。基于Qwen2.5-14B-Instruct,具有独特的总结能力。访问我们的产品页面,探索它如何简化问题解决!
-

DeepCoder:64K 上下文代码 AI。开源 14B 模型超出预期!长程上下文,强化学习训练,顶尖性能。
-

MMStar,用于评估视觉语言模型大规模多模态功能的基准测试集。使用 MMStar,探索模型性能中的潜在问题,并跨多个任务评估其多模态能力。立即尝试!
-
Free, unbiased testing for OCR & VLM models. Evaluate document parsing AI with your own files, get real-world performance insights & rankings.
-

Qwen3 Reranker 助您大幅提升搜索准确度。它能精准地对文本进行排序,跨越百余种语言,助您更迅速地获取所需信息。全面赋能问答系统与文本分析应用。
-

借助 Agent Leaderboard,选择最适合您需求的 AI 智能体——它提供跨 14 项基准的公正、真实的性能洞察。
-

-
Jan-v1:您的本地AI智能体,专为自动化研究而生。助您在本地设备上打造功能强大、私密安全的AI应用,轻松生成专业报告,并无缝集成网页搜索功能,所有数据处理均在本地机器完成。
-