
2025年に最高の ZeroBench 代替ソフト
-

xbench:現実世界での実用性と、フロンティア領域の能力を追跡するAIベンチマーク。独自のデュアルトラックシステムにより、AIエージェントの正確かつ動的な評価を提供します。
-

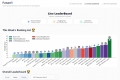
LiveBench は、さまざまなソースからの毎月の新しい質問と正確な採点のための客観的な回答を備えた LLM ベンチマークであり、現在 6 つのカテゴリに 18 のタスクを備えており、さらに多くのタスクが追加される予定です。
-

WildBenchは、現実世界のさまざまなタスクでLLMを評価する、高度なベンチマークツールです。AIのパフォーマンスを向上させ、実際のシナリオにおけるモデルの限界を理解したいと考えている人にとって不可欠です。
-

BenchX: AIエージェントのベンチマークと改善。決定、ログ、メトリクスを追跡。CI/CDに統合。実用的な洞察を入手。
-

Web Benchは、多種多様な実稼働ウェブサイト全体にわたる複雑な現実世界タスクにおいて、AIウェブブラウジングエージェントの性能評価に特化して設計された、新しい、オープンかつ包括的なベンチマークデータセットです。
-

ノーコードのLLM評価で、AI製品をより迅速にローンチしましょう。180種類以上のモデルを比較し、プロンプトを作成し、自信を持ってテストできます。
-
-
PromptBench で大規模言語モデルを簡単に評価しましょう。パフォーマンスを評価し、モデルの機能を強化し、敵対的なプロンプトに対する堅牢性をテストします。
-

TensorZero: オープンソースの統合LLMOpsスタック。高パフォーマンスと確かな信頼性で、プロダクションレベルのLLMアプリケーションを構築・最適化。
-
Voxel51社のFiftyOneは、データとモデルのリファインを実現するプラットフォームです。これにより、容易に、効率的に、そして大規模に、本番環境対応のビジュアルAIアプリケーションを構築できます。
-

BenchLLM: LLMレスポンスを評価し、テストスイートを構築し、評価を自動化します。包括的なパフォーマンス評価により、AI駆動システムを強化します。
-

Braintrust:信頼性の高いAIアプリケーションの開発、テスト、監視を実現するエンドツーエンドプラットフォーム。予測可能で高品質なLLM結果を提供します。
-

ZenbaseはAI開発を簡素化します。プロンプトエンジニアリングとモデル最適化を自動化し、信頼性の高いツール呼び出し、継続的な最適化、そしてエンタープライズグレードのセキュリティを提供します。時間を節約し、よりスマートにスケーリングしましょう。開発者にとって理想的です!
-

-
Design Arena: AIデザインのための、コミュニティ主導の決定版ベンチマーク。モデルを客観的に格付けし、その真のデザイン品質と美的センスを評価します。
-

Geekbench AI は、現実世界の機械学習タスクを使用して AI ワークロードのパフォーマンスを評価する、クロスプラットフォームの AI ベンチマークです。
-

TruthfulQA を使用して言語モデルの真実性を測定します。これは、38 のカテゴリ全体で 817 の質問からなるベンチマークです。誤解に基づく誤った回答を避けてください。
-

深層推論モデルDeepSeek-R1は、強化学習(RL)によって強化された最先端技術であり、数学、コーディング、推論タスクにおいてベンチマークを上回ります。オープンソースでAI駆動です。
-

-

Alpha Arena: AI投資の真価を問う、実世界でのベンチマーク。生きた金融市場に実資金を投じ、AIモデルのパフォーマンスを検証。その実力を証明し、リスクを管理します。
-

Baichuan-M2:実臨床推論のための先進医療AI。診断を支援し、患者の転帰を改善。単一のGPU上でプライベートに展開できます。
-

NetEase Youdao開発の、o1ライクな推論モデルConfucius-o1-14B。シングルGPUで展開可能です。Qwen2.5-14B-Instructをベースとしており、独自の要約能力を備えています。製品ページで、問題解決を簡素化する仕組みをご覧ください!
-

DeepCoder:64KコンテキストコードAI。オープンソースの14Bモデルが期待を上回る性能を発揮!長文コンテキスト、RL(強化学習)トレーニング、トップレベルのパフォーマンス。
-

MMStarは、ビジュアル言語モデルの大規模マルチモーダル機能を評価するためのベンチマークテストセットです。MMStarを使用すると、モデルのパフォーマンスにおける潜在的な問題を発見し、マルチモーダル能力を複数のタスクで評価できます。今すぐ試してみましょう!
-
Free, unbiased testing for OCR & VLM models. Evaluate document parsing AI with your own files, get real-world performance insights & rankings.
-

Qwen3 Rerankerで検索精度を飛躍的に向上させます。100以上の言語に対応し、テキストを正確にランク付けすることで、関連情報をより迅速に発見。質疑応答(Q&A)やテキスト分析の強化にも貢献します。
-

14種類のベンチマークに基づいた、偏りのないリアルな性能評価を提供する「Agent Leaderboard」で、ニーズに最適なAIエージェントを見つけましょう。
-

VERO: LLMパイプライン向けのエンタープライズAI評価フレームワーク。問題を迅速に検出し修正し、数週間にわたるQA作業をわずか数分で確信へと導きます。
-
Jan-v1: リサーチを自動化する、あなたのローカルAIエージェント。 お手元のマシン上で、プライベートかつ高性能なアプリを構築し、プロフェッショナルなレポートの生成やWeb検索の統合を実現します。
-
ZenMuxは、エンタープライズLLMのオーケストレーションを簡素化します。統合API、インテリジェントルーティング、そして画期的なAIモデル保険により、確かな品質と信頼性を保証します。