
2026 Лучших LiveBench Альтернативи
-

WildBench - это передовой инструмент для бенчмаркинга, который оценивает большие языковые модели (LLM) на разнообразном наборе реальных задач. Он незаменим для тех, кто стремится повысить производительность ИИ и понять ограничения модели в практических сценариях.
-

BenchLLM: Оценивайте ответы больших языковых моделей, создавайте наборы тестов, автоматизируйте оценку. Повышайте качество систем на основе ИИ с помощью всесторонней оценки производительности.
-

Запускайте продукты на основе ИИ быстрее с помощью бескликовой оценки больших языковых моделей. Сравнивайте более 180 моделей, создавайте запросы и тестируйте с уверенностью.
-

Компании всех размеров используют Confident AI, чтобы обосновать, почему их LLM заслуживают места в процессе производства.
-

xbench: Бенчмарк ИИ, оценивающий реальную полезность и передовые возможности. Получите точную, динамичную оценку ИИ-агентов с помощью нашей двухканальной системы.
-

Deepchecks: Комплексная платформа для оценки LLM. Систематически тестируйте, сравнивайте и отслеживайте ваши ИИ-приложения от разработки до продакшена. Минимизируйте галлюцинации и ускорьте внедрение.
-

Braintrust: Комплексная платформа для разработки, тестирования и мониторинга надежных ИИ-приложений. Получайте предсказуемые, высококачественные результаты LLM.
-

Изучите таблицу лидеров вызова функций Беркли (также известную как таблица лидеров вызова инструментов Беркли), чтобы увидеть, насколько хорошо большие языковые модели могут вызывать функции (также называемые инструментами) с точностью.
-

Рейтинг открытых языковых моделей Huggingface направлен на поощрение открытого сотрудничества и прозрачности в оценке языковых моделей.
-

Данная таблица лидеров для оценки поставщиков LLM работает на основе данных Klu.ai в режиме реального времени, что позволяет выбрать оптимальный API и модель для ваших нужд.
-

Web Bench представляет собой новый, открытый и всеобъемлющий набор данных для бенчмаркинга, специально разработанный для оценки производительности веб-агентов на основе ИИ в решении сложных, реальных задач на широком спектре действующих веб-сайтов.
-
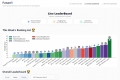
FutureX: Динамически оценивайте прогностические способности LLM-агентов в реальных условиях для предсказания будущих событий. Получите незамутненные инсайты об истинном интеллекте ИИ.
-

BenchX: Инструмент для бенчмаркинга и улучшения AI-агентов. Отслеживайте решения, логи и метрики. Интегрируйте в CI/CD. Получайте практически применимые инсайты.
-

ZeroBench: оптимальный бенчмарк для мультимодальных моделей, проверяющий визуальное мышление, точность и вычислительные навыки с помощью 100 сложных вопросов и 334 подвопросов.
-

Выбирайте лучшего AI-агента, отвечающего вашим потребностям, с помощью Agent Leaderboard — объективного анализа производительности в реальных условиях, основанного на 14 критериях оценки.
-

Оценивайте и улучшайте ваши LLM-приложения с помощью RagMetrics. Автоматизируйте тестирование, измеряйте производительность и оптимизируйте системы RAG для достижения надежных результатов.
-

Хватит гадать, на каком месте ваш AI-поиск. LLMrefs отслеживает ключевые слова в ChatGPT, Gemini и других системах. Получите свой LLMrefs Score и опередите конкурентов!
-

Рейтинг SEAL демонстрирует, что семейство больших языковых моделей (LLM) GPT от OpenAI занимает первое место в трех из четырех начальных областей, которые они используют для ранжирования моделей ИИ, а популярный Claude 3 Opus от Anthropic PBC занимает первое место в четвертой категории. Модели Gemini от Google LLC также показали хорошие результаты, разделив первое место с моделями GPT в паре областей.
-

LightEval — это легкий набор инструментов для оценки больших языковых моделей (LLM), который Hugging Face использует внутри компании с недавно выпущенными библиотеками для обработки данных LLM datatrove и для обучения LLM nanotron.
-
Легко оценивайте большие языковые модели с помощью PromptBench. Оценивайте производительность, улучшайте возможности модели и проверяйте устойчивость к вредоносным запросам.
-

Получайте надежные и проверенные ответы с LLM Council. Наша ИИ-система использует несколько языковых моделей (LLM) и механизм рецензирования для формирования глубоких, объективных инсайтов по сложным запросам.
-

Geekbench AI - это кроссплатформенный бенчмарк для ИИ, который использует реальные задачи машинного обучения для оценки производительности рабочих нагрузок ИИ.
-
Stax: Развертывайте LLM-приложения с уверенностью. Оценивайте модели ИИ и промты, опираясь на ваши уникальные критерии, для получения глубоких выводов, основанных на данных. Развивайте ИИ лучше и быстрее.
-

Сравнивайте результаты работы ChatGPT, Claude и Gemini мгновенно, используя один и тот же запрос. Наша платформа идеально подходит для исследователей, создателей контента и энтузиастов ИИ, помогая вам выбрать лучшую языковую модель для ваших задач, гарантируя оптимальные результаты и эффективность.
-
Evaligo: Ваша единая платформа для разработки ИИ. Создавайте, тестируйте и контролируйте промпты для продакшна, чтобы масштабно внедрять надежные ИИ-возможности. Предотвращайте дорогостоящие регрессии.
-

Столкнулись с трудностями при выпуске надежных LLM-приложений? Parea AI помогает командам ИИ в оценке, отладке и мониторинге ваших ИИ-систем, охватывая весь цикл: от разработки до продакшна. Выпускайте с уверенностью.
-
Weights & Biases: Единая ИИ-платформа для разработчиков, предназначенная для ускоренного создания, оценки и управления ML-моделями, LLM и агентами.
-

Literal AI: Наблюдаемость и оценка для RAG и LLM. Отладка, мониторинг, оптимизация производительности и обеспечение готовности к эксплуатации приложений AI.
-

AutoArena - это инструмент с открытым исходным кодом, который автоматизирует сравнительные оценки с использованием судей LLM для ранжирования систем GenAI. Быстро и точно создавайте таблицы лидеров, сравнивая различные LLMs, конфигурации RAG или варианты подсказок. Настройте пользовательских судей в соответствии со своими потребностями.
-

Используйте OpenAI для вызова всех API LLM. Используйте Bedrock, Azure, OpenAI, Cohere, Anthropic, Ollama, Sagemaker, HuggingFace, Replicate (свыше 100 LLM)