
최상의 LiveBench 대체품 2026년
-

WildBench는 다양한 실제 작업 세트에서 LLM을 평가하는 고급 벤치마킹 도구입니다. 실제 시나리오에서 AI 성능을 향상시키고 모델의 한계를 이해하려는 사람들에게 필수적입니다.
-

BenchLLM: LLM 응답 평가, 테스트 세트 구축, 평가 자동화. 포괄적인 성능 평가를 통해 AI 기반 시스템을 향상시킵니다.
-

노코드 LLM 평가로 AI 제품 출시 속도를 높이세요. 180개 이상의 모델을 비교하고, 프롬프트를 만들고, 자신 있게 테스트하세요.
-

모든 규모의 회사가 Confident AI를 사용하여 자사의 LLM이 운영에 적합한 이유를 정당화하고 있습니다.
-

xbench: 실제 활용성과 최첨단 역량을 측정하는 AI 벤치마크. 당사의 듀얼 트랙 시스템으로 AI 에이전트의 정확하고 역동적인 평가를 제공합니다.
-

Deepchecks: LLM 평가를 위한 종합 플랫폼. 개발부터 배포까지 귀하의 AI 앱을 체계적으로 테스트하고, 비교하며, 모니터링하세요. 환각 현상을 줄이고 더 빠르게 배포하세요.
-

Braintrust: 신뢰도 높은 AI 애플리케이션의 개발, 테스트, 모니터링을 위한 엔드-투-엔드 플랫폼. 예측 가능하고 고품질의 LLM 결과를 제공합니다.
-

Berkeley 함수 호출 리더보드(Berkeley 툴 호출 리더보드라고도 함)를 탐색하여 LLM이 함수(또는 툴)를 정확하게 호출하는 능력을 확인해 보세요.
-

Huggingface의 Open LLM Leaderboard는 언어 모델 평가에 대한 개방적인 협업과 투명성을 촉진하기 위한 목표를 가지고 있습니다.
-

실시간 Klu.ai 데이터는 LLM 제공업체를 평가하기 위한 이 리더보드를 구동하여 사용자의 요구에 맞는 최적의 API 및 모델을 선택할 수 있도록 지원합니다.
-

Web Bench는 다양한 실제 웹사이트에서 마주하는 복잡하고 현실적인 과제에 대한 AI 웹 브라우징 에이전트의 성능을 평가하기 위해 특별히 고안된, 새롭고 개방적이며 포괄적인 벤치마크 데이터셋입니다.
-
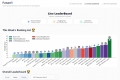
FutureX: LLM 에이전트가 현실 세계의 미래 사건을 얼마나 정확하게 예측하는지 실시간으로 평가합니다. 이를 통해 진정한 AI 지능에 대한 순수하고 편향 없는 통찰력을 확보하세요.
-

BenchX: AI 에이전트의 성능을 벤치마크하고 개선하세요. 의사 결정, 로그, 그리고 메트릭을 추적하고 CI/CD에 통합하여 실행 가능한 통찰력을 얻으세요.
-

ZeroBench: 멀티모달 모델을 위한 궁극적인 벤치마크로서, 시각적 추론, 정확성, 그리고 연산 능력을 시험하는 100개의 도전적인 질문과 334개의 하위 질문으로 구성되어 있습니다.
-

Agent Leaderboard를 통해 귀사의 요구사항에 가장 적합한 AI 에이전트를 선택하십시오. 14개의 벤치마크 전반에 걸쳐 편향 없는 실제 성능 통찰력을 제공합니다.
-

RagMetrics를 활용하여 LLM 애플리케이션을 평가하고 개선하세요. 자동화된 테스트를 통해 성능을 측정하고, 신뢰할 수 있는 결과를 위해 RAG 시스템을 최적화하십시오.
-

AI 검색 순위를 그만 추측하세요. LLMrefs는 ChatGPT, Gemini 등에서 키워드를 추적합니다. LLMrefs 점수를 획득하고 경쟁사보다 앞서 나가세요!
-

SEAL 리더보드에 따르면 OpenAI의 GPT 계열 LLM은 AI 모델을 평가하는 데 사용되는 초기 4개 도메인 중 3개에서 1위를 차지했습니다. Anthropic PBC의 인기 모델인 Claude 3 Opus는 나머지 하나의 카테고리에서 1위를 차지했습니다. Google LLC의 Gemini 모델도 좋은 성적을 거두어 몇몇 도메인에서 GPT 모델과 공동 1위를 차지했습니다.
-

LightEval은 Hugging Face에서 최근 출시된 LLM 데이터 처리 라이브러리 datatrove와 LLM 훈련 라이브러리 nanotron과 함께 내부적으로 사용하고 있는 경량 LLM 평가 도구 모음입니다.
-
PromptBench를 사용하여 대규모 언어 모델 평가를 간편하게 수행합니다. 성능을 평가하고, 모델 기능을 향상시키며, 적대적 프롬프트에 대한 견고성을 테스트하세요.
-

LLM Council로 신뢰할 수 있고 검증된 답변을 얻으세요. 당사의 AI 시스템은 여러 LLM과 동료 검토(Peer Review)를 활용해 복잡한 질문에 대해 깊이 있고 편향되지 않은 인사이트를 종합합니다.
-

Geekbench AI는 실제 머신러닝 작업을 사용하여 AI 워크로드 성능을 평가하는 크로스 플랫폼 AI 벤치마크입니다.
-
-

단일 프롬프트를 사용하여 ChatGPT, Claude, Gemini의 출력을 나란히 즉시 비교해 보세요. 연구자, 콘텐츠 제작자, AI 애호가에게 완벽한 저희 플랫폼은 사용자의 요구에 가장 적합한 언어 모델을 선택하는 데 도움을 주어 최적의 결과와 효율성을 보장합니다.
-
Evaligo: 당신의 올인원 AI 개발 플랫폼. 대규모로 안정적인 AI 기능을 배포하기 위한 프로덕션 프롬프트 구축, 테스트 및 모니터링을 지원합니다. 값비싼 회귀 현상도 미연에 방지할 수 있습니다.
-

신뢰할 수 있는 LLM 앱 배포에 어려움을 겪고 계신가요? Parea AI는 AI 팀이 개발부터 프로덕션까지 AI 시스템을 평가, 디버깅 및 모니터링할 수 있도록 지원합니다. 이제 자신 있게 배포하세요.
-
Weights & Biases: ML, LLM, 에이전트의 개발, 평가, 관리를 가속화하는 통합 AI 개발자 플랫폼.
-

Literal AI: RAG 및 LLM을 위한 관측 가능성 및 평가. 디버깅, 모니터링, 성능 최적화를 통해 프로덕션 환경에 바로 적용 가능한 AI 앱을 보장합니다.
-

AutoArena는 LLM 심판을 사용하여 헤드투헤드 평가를 자동화하여 GenAI 시스템을 순위 매기는 오픈 소스 도구입니다. 다양한 LLM, RAG 설정 또는 프롬프트 변형을 비교하는 리더보드를 빠르고 정확하게 생성합니다. 필요에 맞게 맞춤형 심판을 미세 조정하세요.
-

OpenAI 형식을 사용하여 모든 LLM API를 호출합니다. Bedrock, Azure, OpenAI, Cohere, Anthropic, Ollama, Sagemaker, HuggingFace, Replicate(100개 이상의 LLM)을 사용합니다.