
Las mejores LiveBench alternativas en 2026
-

WildBench es una herramienta de evaluación avanzada que evalúa los LLM en un conjunto diverso de tareas del mundo real. Es esencial para aquellos que buscan mejorar el rendimiento de la IA y comprender las limitaciones del modelo en escenarios prácticos.
-

BenchLLM: Evalúe las respuestas de LLM, cree conjuntos de pruebas, automatice las evaluaciones. Mejore los sistemas impulsados por IA con evaluaciones de rendimiento integrales.
-

Lanza productos de IA más rápido con evaluaciones LLM sin código. Compara más de 180 modelos, crea prompts y prueba con confianza.
-

Las empresas de todos los tamaños utilizan Confident AI para justificar por qué su LLM merece estar en producción.
-

xbench: El referente de IA que mide la utilidad en entornos reales y las capacidades de vanguardia. Obtenga una evaluación precisa y dinámica de los agentes de IA con nuestro sistema de doble vía.
-

Deepchecks: La plataforma integral para la evaluación de LLM. Ponga a prueba, compare y monitorice sistemáticamente sus aplicaciones de IA del desarrollo a la producción. Reduzca las alucinaciones y despliegue más rápido.
-

Braintrust: La plataforma integral para desarrollar, probar y monitorizar aplicaciones de IA fiables. Obtenga resultados de LLM predecibles y de alta calidad.
-

Explora el Berkeley Function Calling Leaderboard (también llamado Berkeley Tool Calling Leaderboard) para ver la capacidad de los LLM para llamar funciones (también conocidas como herramientas) con precisión.
-

El Leaderboard de Modelos de Lenguaje Abiertos de Huggingface tiene como objetivo fomentar la colaboración abierta y la transparencia en la evaluación de modelos de lenguaje.
-

Los datos de Klu.ai en tiempo real impulsan esta tabla de clasificación para evaluar proveedores de LLM, permitiendo la selección de la API y el modelo óptimos para sus necesidades.
-

Web Bench es un conjunto de datos de evaluación comparativa (benchmark) novedoso, abierto e integral, diseñado específicamente para evaluar el rendimiento de los agentes de IA de navegación web en tareas complejas y del mundo real, que abarcan una amplia diversidad de sitios web activos.
-
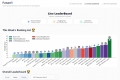
FutureX: Evalúe dinámicamente la capacidad predictiva de los agentes LLM para eventos futuros en el mundo real. Obtenga perspectivas sin adulterar sobre la auténtica inteligencia artificial.
-

BenchX: Evalúa y mejora agentes de IA. Realiza un seguimiento de las decisiones, los registros y las métricas. Intégralo en CI/CD. Obtén información práctica y útil.
-

ZeroBench: El punto de referencia definitivo para modelos multimodales, que pone a prueba el razonamiento visual, la precisión y las habilidades computacionales con 100 preguntas desafiantes y 334 subpreguntas.
-

Seleccione el mejor agente de IA para sus necesidades con la Agent Leaderboard: análisis de rendimiento imparciales y del mundo real en 14 pruebas de referencia.
-

Evalúa y mejora tus aplicaciones de LLM con RagMetrics. Automatiza las pruebas, mide el rendimiento y optimiza los sistemas RAG para obtener resultados fiables.
-

Deja de adivinar tu posición en las búsquedas de IA. LLMrefs rastrea palabras clave en ChatGPT, Gemini y más. ¡Obtén tu LLMrefs Score y supera a la competencia!
-

Las tablas de clasificación de SEAL muestran que la familia GPT de LLMs de OpenAI ocupa el primer lugar en tres de los cuatro dominios iniciales que utiliza para clasificar los modelos de IA, mientras que Claude 3 Opus, el popular modelo de Anthropic PBC, se lleva el primer lugar en la cuarta categoría. Los modelos Gemini de Google LLC también se desempeñaron bien, ocupando el primer lugar junto con los modelos GPT en un par de los dominios.
-

LightEval es un conjunto de evaluación de LLM ligero que Hugging Face ha estado utilizando internamente con la biblioteca de procesamiento de datos de LLM recientemente lanzada datatrove y la biblioteca de entrenamiento de LLM nanotron.
-
Evalúa modelos de lenguaje grandes fácilmente con PromptBench. Evalúa el rendimiento, mejora las capacidades del modelo y prueba la robustez frente a indicaciones adversas.
-

Obtén respuestas sólidas y rigurosamente evaluadas con el LLM Council. Nuestro sistema de IA utiliza múltiples LLMs y revisiones por pares para sintetizar conocimientos profundos e imparciales ante consultas complejas.
-

Geekbench AI es un punto de referencia de IA multiplataforma que utiliza tareas de aprendizaje automático del mundo real para evaluar el rendimiento de la carga de trabajo de IA.
-
Stax: Despliega tus aplicaciones LLM con total confianza. Evalúa modelos y prompts de AI según tus criterios exclusivos para obtener perspectivas basadas en datos. Desarrolla una AI superior, con mayor agilidad.
-

Compara instantáneamente las salidas de ChatGPT, Claude y Gemini lado a lado utilizando un solo prompt. Perfecto para investigadores, creadores de contenido y entusiastas de la IA, nuestra plataforma te ayuda a elegir el mejor modelo de lenguaje para tus necesidades, asegurando resultados óptimos y eficiencia.
-
Evaligo: Tu plataforma integral para el desarrollo de IA. Crea, prueba y monitoriza prompts de producción para desplegar funcionalidades de IA fiables a gran escala. Evita costosas regresiones.
-

¿Le cuesta desplegar aplicaciones LLM fiables? Parea AI ayuda a los equipos de IA a evaluar, depurar y monitorizar sus sistemas de IA del desarrollo a la producción. Despliegue con confianza.
-
Weights & Biases: La plataforma unificada para desarrolladores de IA para construir, evaluar y gestionar ML, LLMs y agentes con mayor rapidez.
-

Literal AI: Observabilidad y Evaluación para RAG y LLMs. Depura, monitoriza, optimiza el rendimiento y garantiza aplicaciones de IA listas para producción.
-

AutoArena es una herramienta de código abierto que automatiza las evaluaciones de cabeza a cabeza utilizando jueces LLM para clasificar los sistemas GenAI. Genera rápidamente y con precisión tablas de clasificación que comparan diferentes LLM, configuraciones RAG o variaciones de indicaciones. Ajusta jueces personalizados para que se adapten a tus necesidades.
-

Invocar todas las API de LLM utilizando el formato OpenAI. Usar Bedrock, Azure, OpenAI, Cohere, Anthropic, Ollama, Sagemaker, HuggingFace, Replicate (más de 100 LLM)