
Las mejores Belebele alternativas en 2025
-

LiveBench es un punto de referencia para LLM con nuevas preguntas mensuales de diversas fuentes y respuestas objetivas para una puntuación precisa, actualmente con 18 tareas en 6 categorías y más por venir.
-

ZeroBench: El punto de referencia definitivo para modelos multimodales, que pone a prueba el razonamiento visual, la precisión y las habilidades computacionales con 100 preguntas desafiantes y 334 subpreguntas.
-

WildBench es una herramienta de evaluación avanzada que evalúa los LLM en un conjunto diverso de tareas del mundo real. Es esencial para aquellos que buscan mejorar el rendimiento de la IA y comprender las limitaciones del modelo en escenarios prácticos.
-

Descubre el poder de The Pile, un conjunto de datos idiomáticos de código abierto de 825 GiB de EleutherAI. Entrena modelos con capacidades de generalización más amplias.
-

Lanza productos de IA más rápido con evaluaciones LLM sin código. Compara más de 180 modelos, crea prompts y prueba con confianza.
-
Evalúa modelos de lenguaje grandes fácilmente con PromptBench. Evalúa el rendimiento, mejora las capacidades del modelo y prueba la robustez frente a indicaciones adversas.
-

GLM-130B: un modelo preentrenado bilingüe abierto (ICLR 2023)
-

BenchLLM: Evalúe las respuestas de LLM, cree conjuntos de pruebas, automatice las evaluaciones. Mejore los sistemas impulsados por IA con evaluaciones de rendimiento integrales.
-

Las tablas de clasificación de SEAL muestran que la familia GPT de LLMs de OpenAI ocupa el primer lugar en tres de los cuatro dominios iniciales que utiliza para clasificar los modelos de IA, mientras que Claude 3 Opus, el popular modelo de Anthropic PBC, se lleva el primer lugar en la cuarta categoría. Los modelos Gemini de Google LLC también se desempeñaron bien, ocupando el primer lugar junto con los modelos GPT en un par de los dominios.
-

OpenCompass es un conjunto de aplicaciones y una plataforma de evaluación completa, eficiente y de código abierto, diseñado para grandes modelos.
-

Explora el Berkeley Function Calling Leaderboard (también llamado Berkeley Tool Calling Leaderboard) para ver la capacidad de los LLM para llamar funciones (también conocidas como herramientas) con precisión.
-

MMStar, un conjunto de pruebas de referencia para la evaluación de las funciones multimodales a gran escala de los modelos de lenguaje visual. Descubre problemas potenciales en el rendimiento de tu modelo y evalúa sus capacidades multimodales en múltiples tareas con MMStar. ¡Pruébalo ahora!
-

Mide la veracidad de los modelos de lenguaje con TruthfulQA, un índice de referencia de 817 preguntas en 38 categorías. Evita las respuestas falsas basadas en conceptos erróneos.
-

LightEval es un conjunto de evaluación de LLM ligero que Hugging Face ha estado utilizando internamente con la biblioteca de procesamiento de datos de LLM recientemente lanzada datatrove y la biblioteca de entrenamiento de LLM nanotron.
-
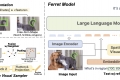
Recopila información básica con precisión y flexibilidad gracias a Ferret. Sus funciones avanzadas potencian el procesamiento del lenguaje natural, los asistentes virtuales y la investigación en IA.
-

Web Bench es un conjunto de datos de evaluación comparativa (benchmark) novedoso, abierto e integral, diseñado específicamente para evaluar el rendimiento de los agentes de IA de navegación web en tareas complejas y del mundo real, que abarcan una amplia diversidad de sitios web activos.
-
Una familia de modelos de lenguaje pionera para aplicaciones de IA avanzadas. Explore modelos de código abierto eficientes con escalado capa por capa para mayor precisión.
-

El Leaderboard de Modelos de Lenguaje Abiertos de Huggingface tiene como objetivo fomentar la colaboración abierta y la transparencia en la evaluación de modelos de lenguaje.
-

Evalúa y mejora tus aplicaciones de LLM con RagMetrics. Automatiza las pruebas, mide el rendimiento y optimiza los sistemas RAG para obtener resultados fiables.
-

El modelo SFR-Embedding-Mistral representa un avance significativo en los modelos de incrustación de texto, basándose en los sólidos cimientos de E5-mistral-7b-instruct y Mistral-7B-v0.1.
-

¡Investigación de IA de código abierto! CleverBee te brinda control y transparencia. Explora, resume y cita fuentes utilizando múltiples LLMs. Basado en Python.
-

Eagle 7B: superando a los transformadores con 1 billón de tokens en más de 100 idiomas (RWKV-v5)
-
PolyLM, un revolucionario modelo lingüístico poliglota (LLM), admite 18 idiomas, sobresale en diversas tareas y es de código abierto. Ideal para desarrolladores, investigadores y empresas con necesidades multilingües.
-
Felo Search es un motor de búsqueda multilingüe avanzado impulsado por IA que proporciona información completa, confiable y libre de sesgos para diversas necesidades.
-

OpenBMB: Creación de un centro de modelos de lenguaje preentrenados a gran escala y herramientas para acelerar la formación, el ajuste y la inferencia de modelos grandes con más de 10 mil millones de parámetros. Únete a nuestra comunidad de código abierto y haz que los modelos grandes lleguen a todos.
-

EasyFinetune ofrece conjuntos de datos diversos y seleccionados para el afinamiento de LLM. Opciones personalizadas disponibles. Agilice el flujo de trabajo y acelere la optimización del modelo. ¡Desbloquea el potencial de LLM!
-
OpenBioLLM-8B es un modelo de lenguaje de código abierto avanzado diseñado específicamente para el dominio biomédico.
-

Cambrian-1 es una familia de modelos lingüísticos de gran tamaño (LLM) multimodales con un diseño centrado en la visión.
-
Descubre el poder de BeeBee AI, una versátil herramienta de software para recopilación, análisis y visualización de datos. Impulsa el éxito en estudios de mercado, análisis financieros e inteligencia competitiva con información valiosa.
-

Dataset Fácil: Cree datos de entrenamiento de IA sin esfuerzo a partir de sus documentos. Ajuste modelos LLM con conjuntos de datos de preguntas y respuestas personalizados. Fácil de usar y compatible con el formato OpenAI.